Cache vetorial
Uma biblioteca Python para cache de consulta eficiente de LLM
Destaque
23 Votos
Descrição
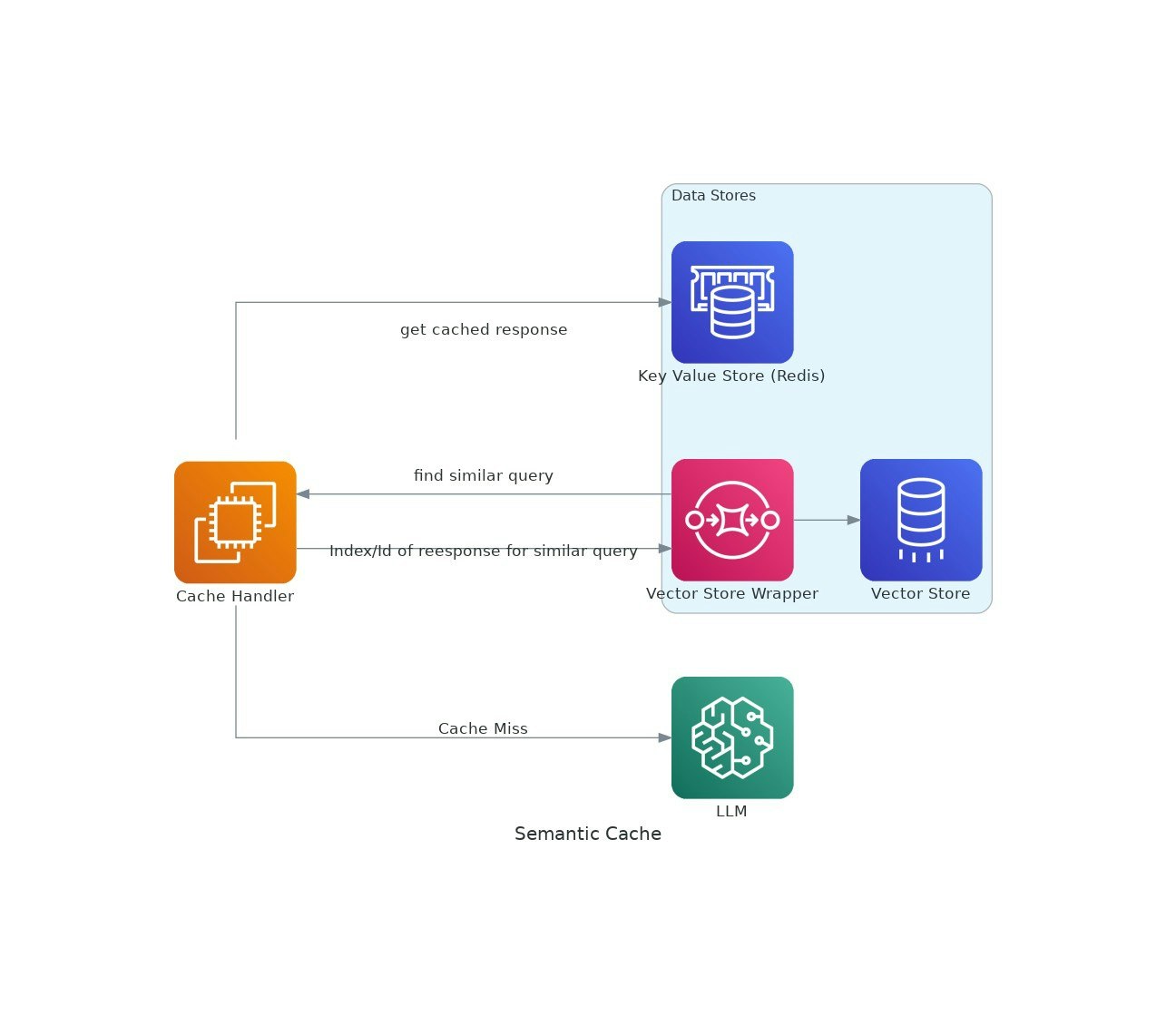
À medida que os aplicativos de IA ganham tração, os custos e a latência do uso de grandes modelos de idiomas (LLMS) podem escalar.O VectorCache aborda essas questões ao cachar as respostas LLM com base na similaridade semântica, reduzindo assim os custos e os tempos de resposta.