G.
Hyperfast LLM em execução em GPUs construídas personalizadas
Destaque
213 Votos

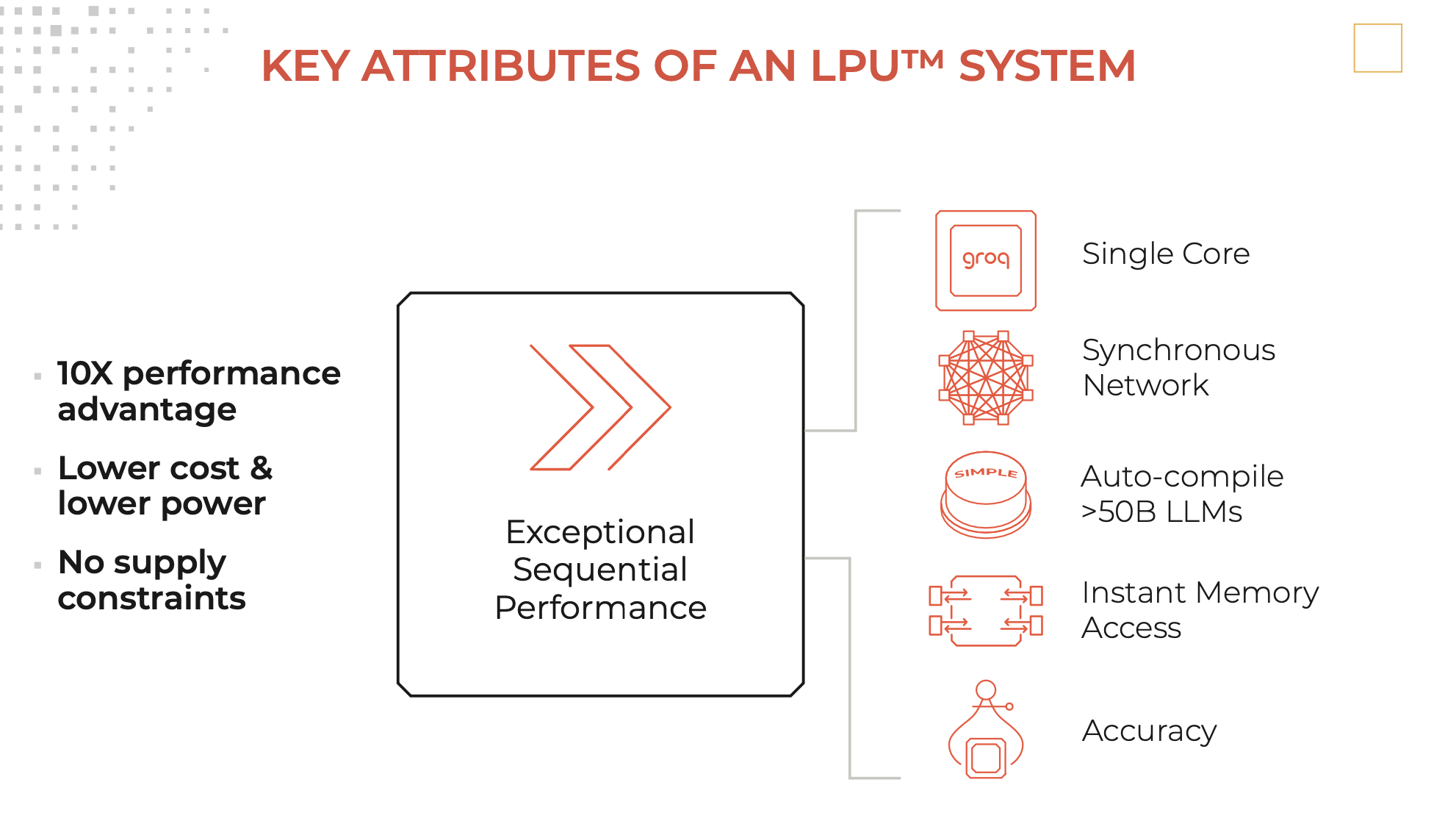

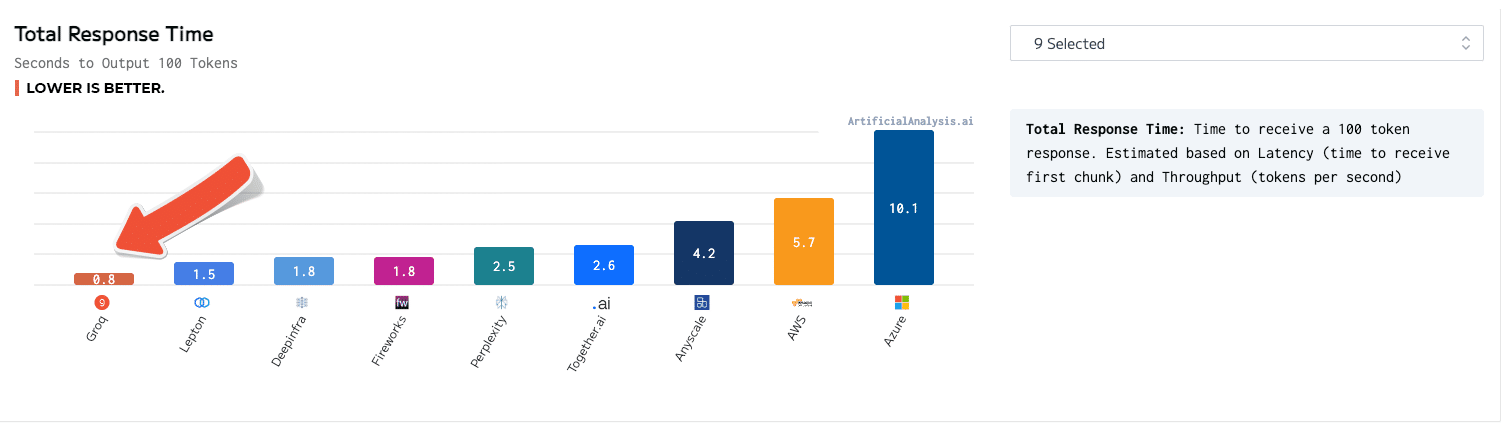
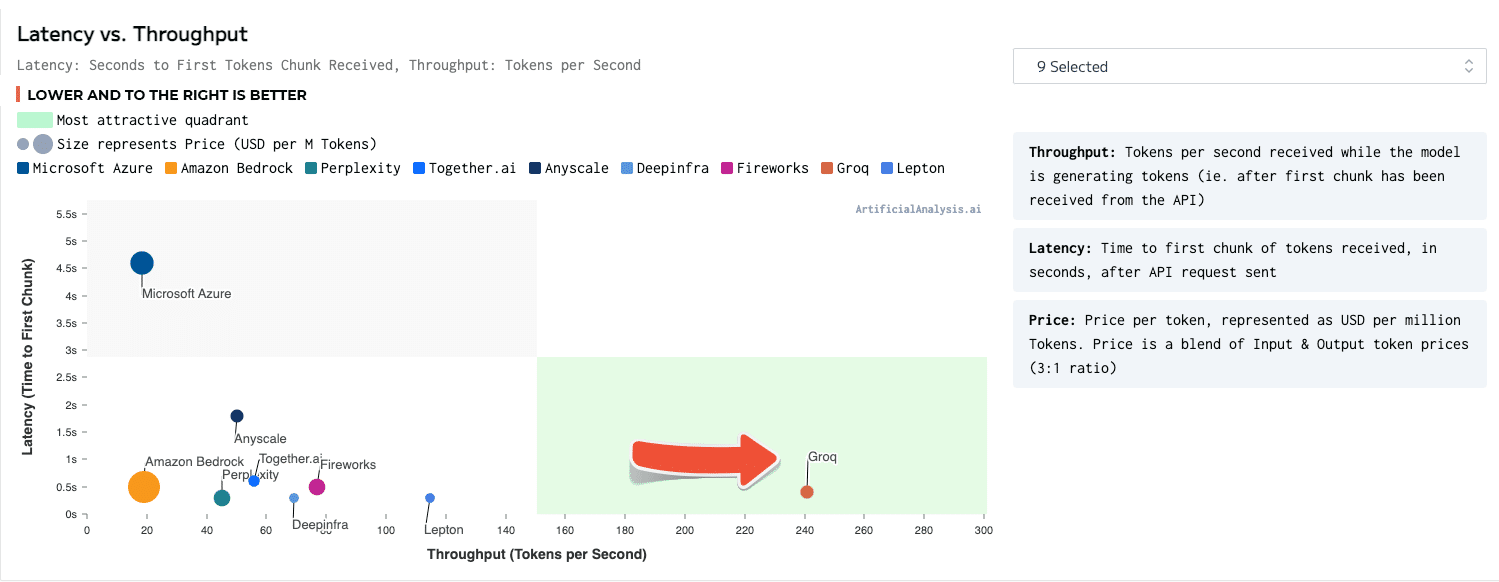
Descrição
Um mecanismo de inferência da LPU, com a LPU no Language Processing Unit ™, é um novo tipo de sistema de unidade de processamento de ponta a ponta que fornece a inferência mais rápida em ~ 500 tokens/segundo.