FlashMla
Inferência mais rápida de LLM nas GPUs Hopper
Destaque
5 Votos

Descrição
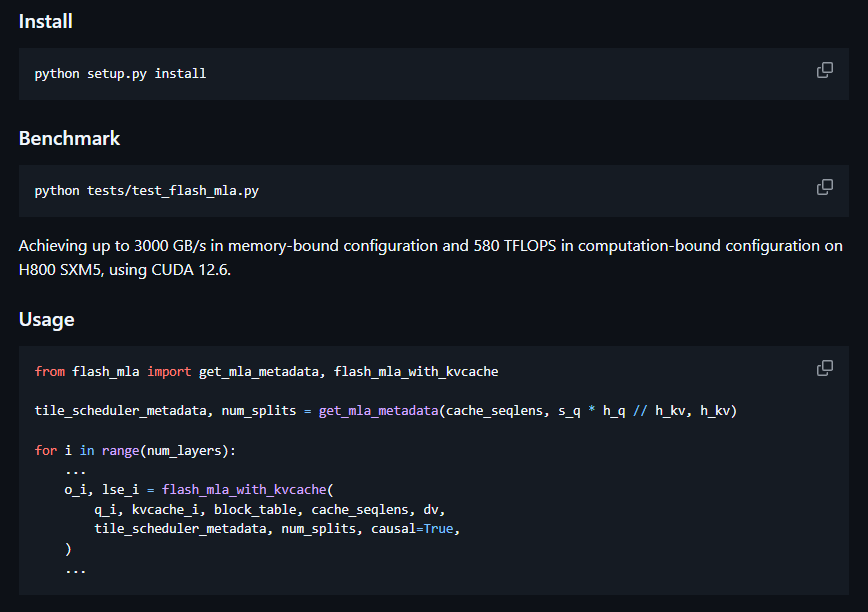
O FlashMla, da Deepseek, é um kernel de decodificação de MLA eficiente para GPUs de Hopper, otimizado para sequências de comprimento variável.Atinge até 3000 GB/s de largura de banda de memória e 580 tflops.