Vector cache
Een Python -bibliotheek voor efficiënte LLM Query Caching
Uitgelicht
23 Stemmen
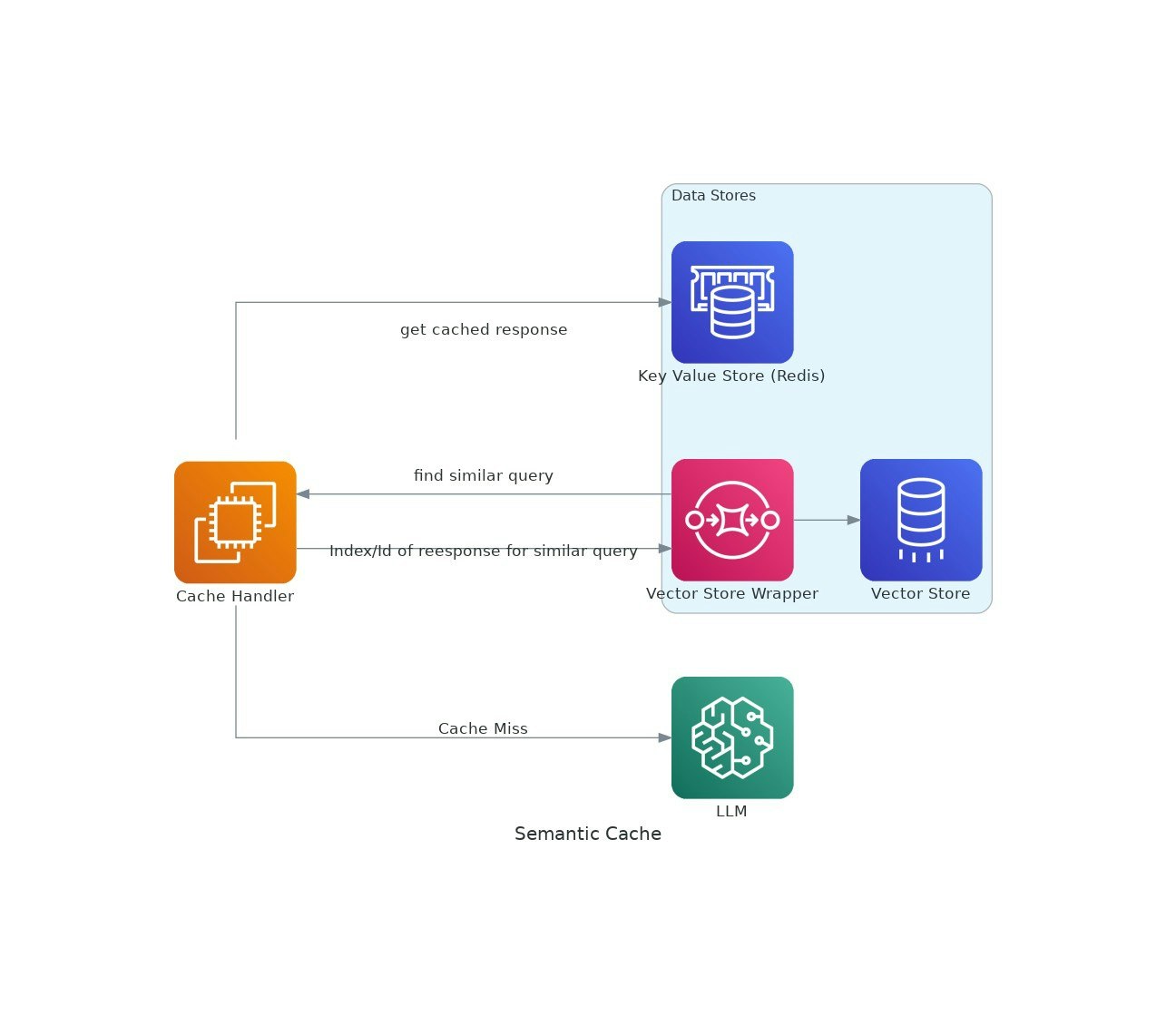
Beschrijving
Omdat AI -toepassingen grip krijgen, kunnen de kosten en latentie van het gebruik van grote taalmodellen (LLMS) escaleren.VectorCache behandelt deze problemen door LLM -reacties te cachen op basis van semantische gelijkenis, waardoor zowel de kosten als de responstijden worden verminderd.