G.
Hyperfast LLM uitgevoerd op op maat gemaakte GPU's
Uitgelicht
213 Stemmen


Beschrijving
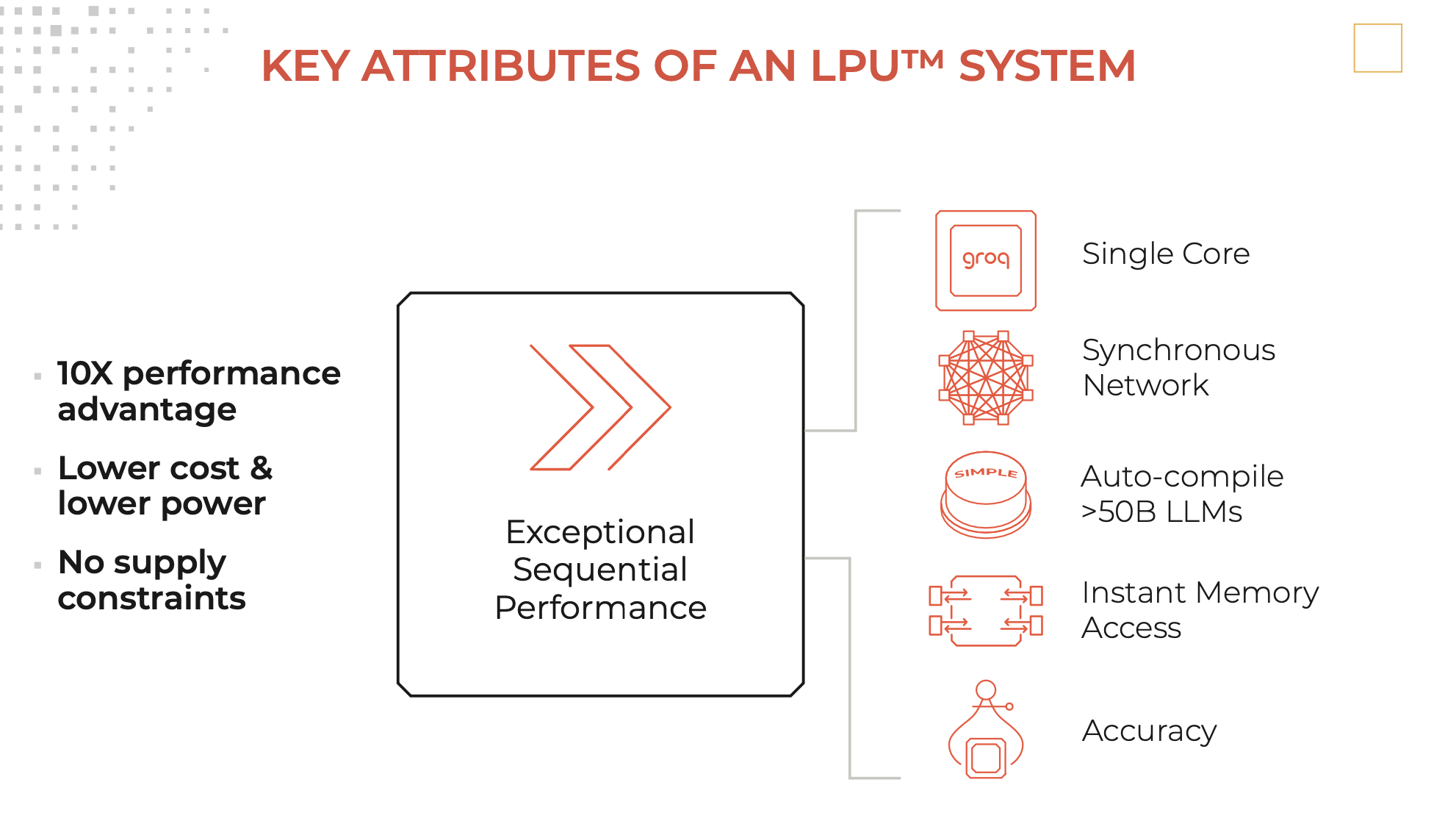
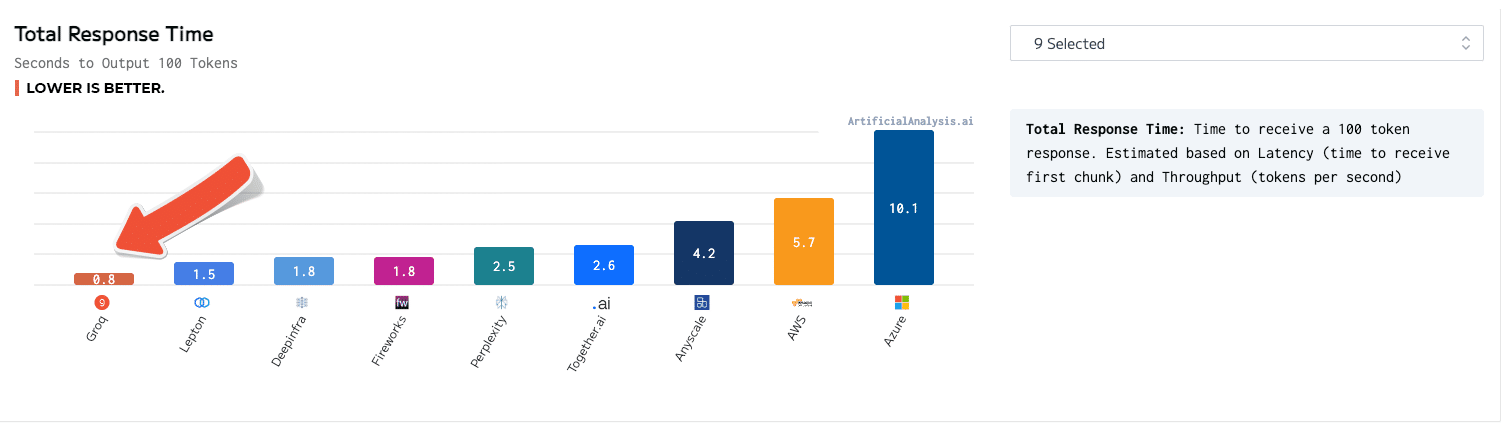
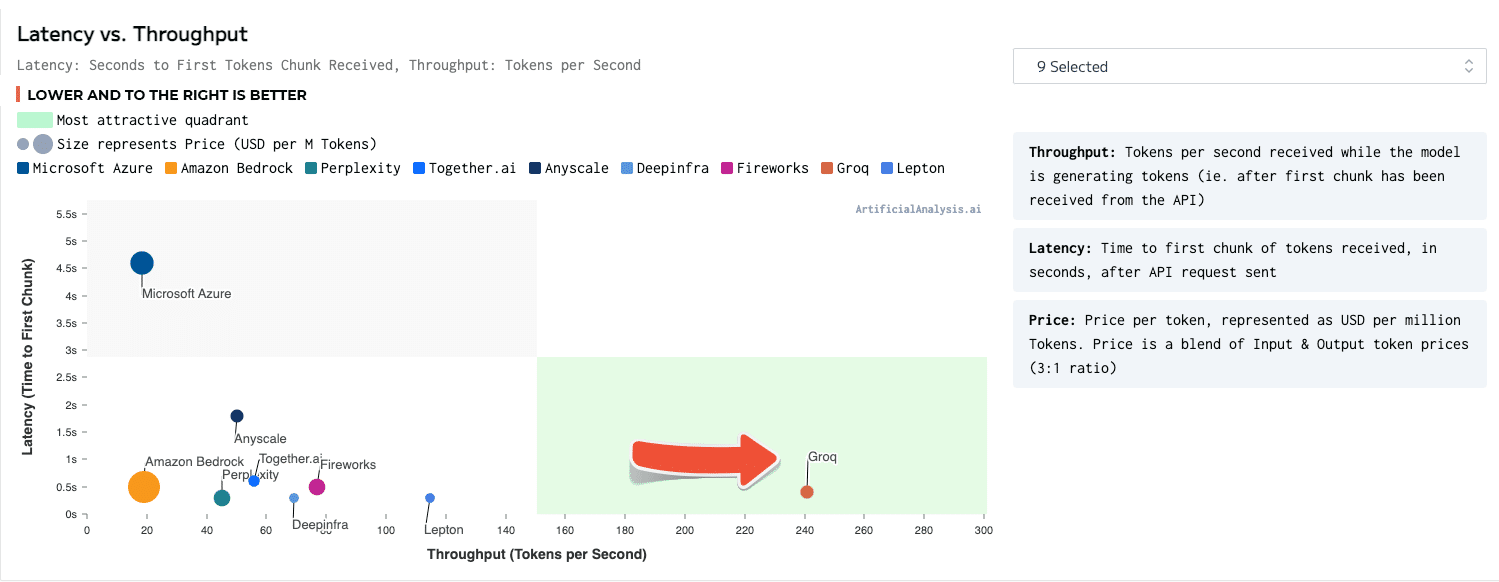
Een LPU-inferentiemotor, met LPU die staat voor taalverwerkingseenheid ™, is een nieuw type end-to-end verwerkingseenheidssysteem dat de snelste inferentie biedt bij ~ 500 tokens/seconde.