Cache vettoriale
Una biblioteca Python per efficiente cache di query LLM
In Evidenza
23 Voti
Descrizione
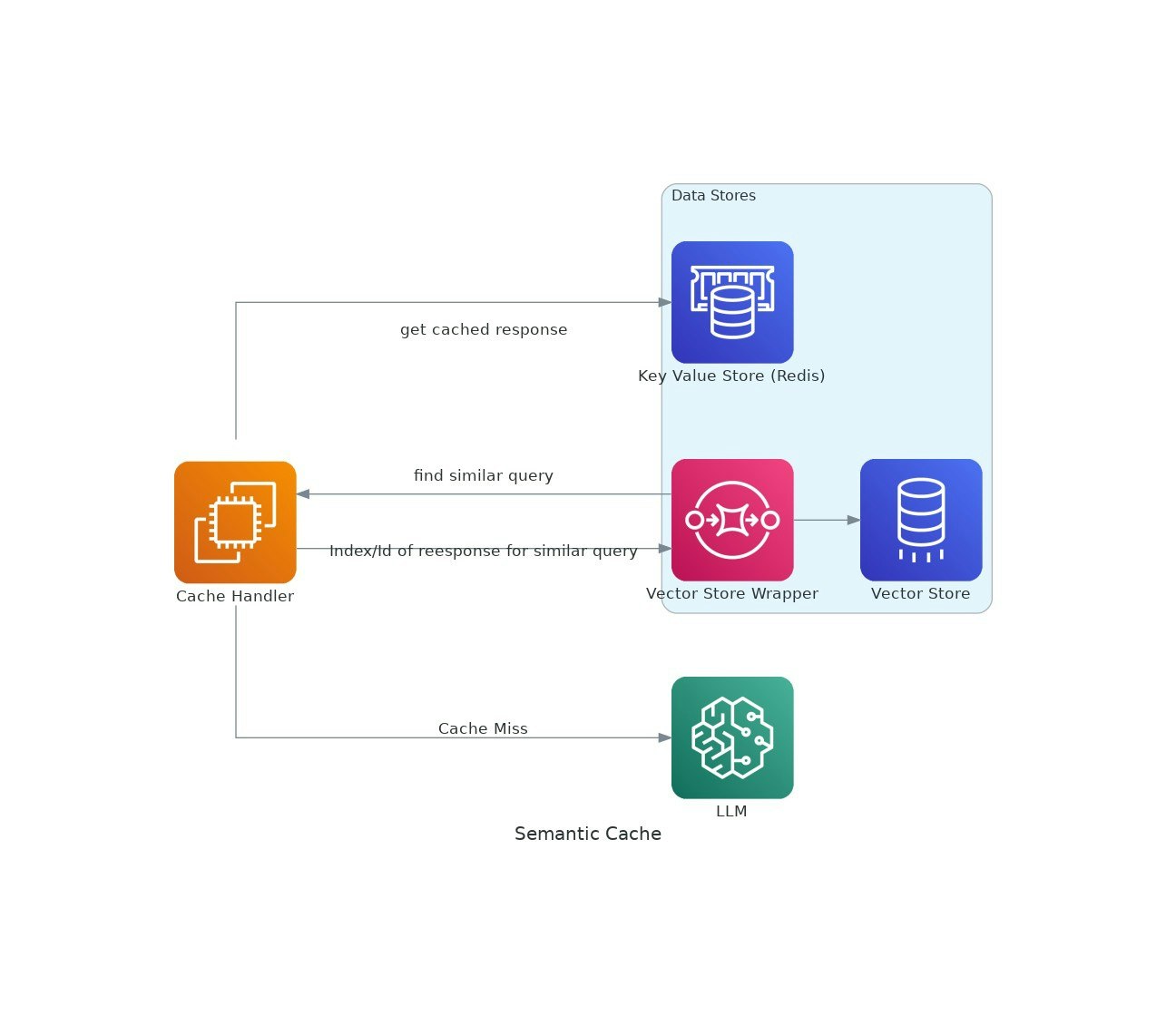
Man mano che le applicazioni AI ottengono trazione, i costi e la latenza dell'utilizzo di modelli di grandi dimensioni (LLM) possono intensificarsi.VectorCache affronta questi problemi memorizzati nella memorizzazione nella cache delle risposte LLM in base alla somiglianza semantica, riducendo così sia i costi che i tempi di risposta.