G.
Hyperfast LLM in esecuzione su GPU personalizzate
In Evidenza
213 Voti

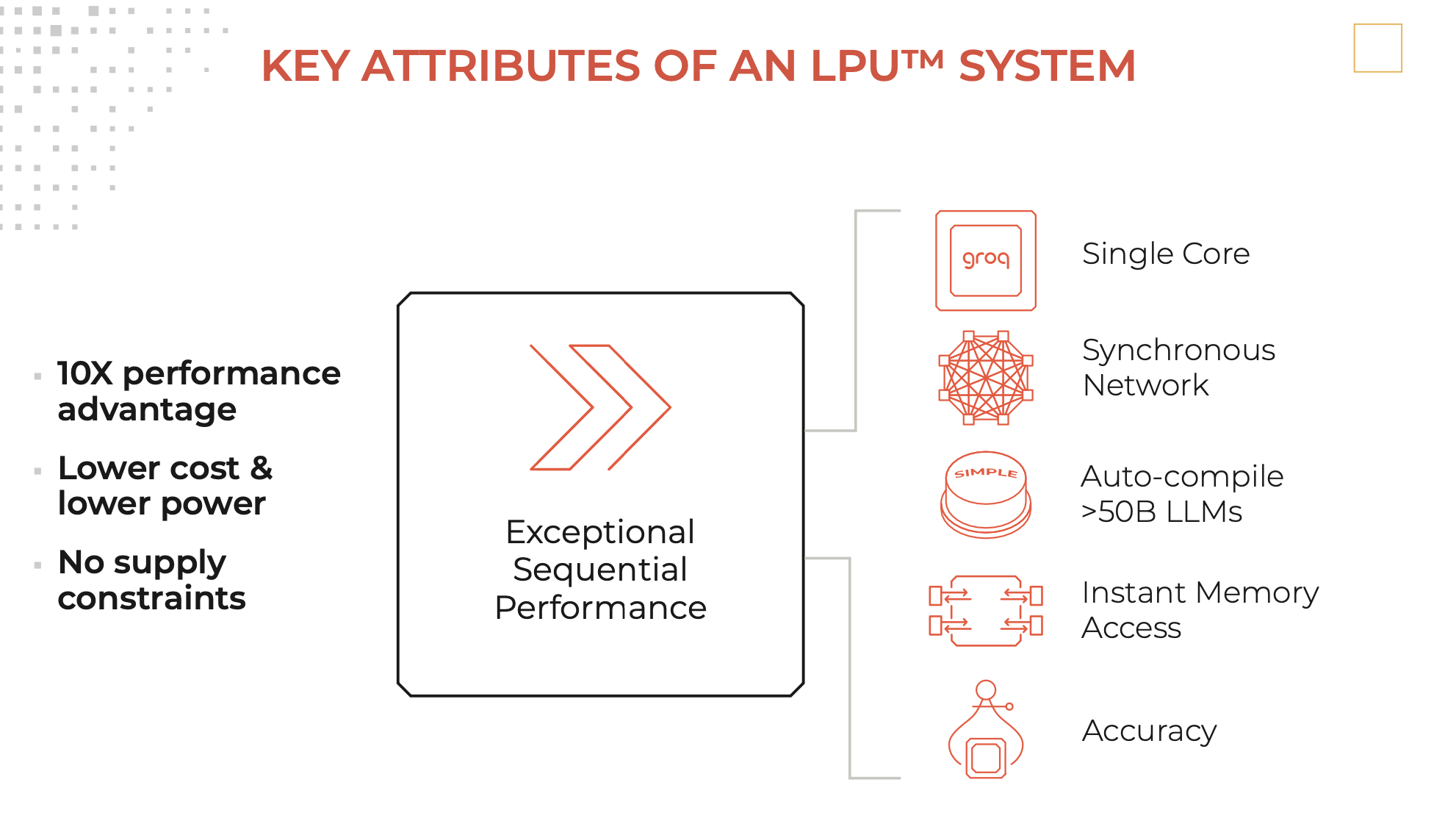

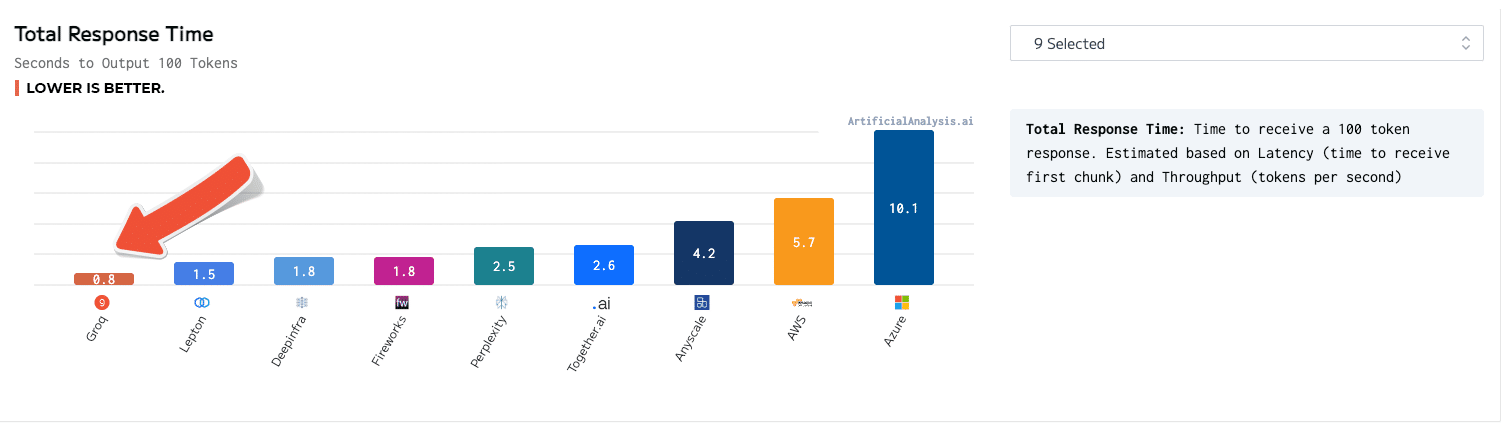
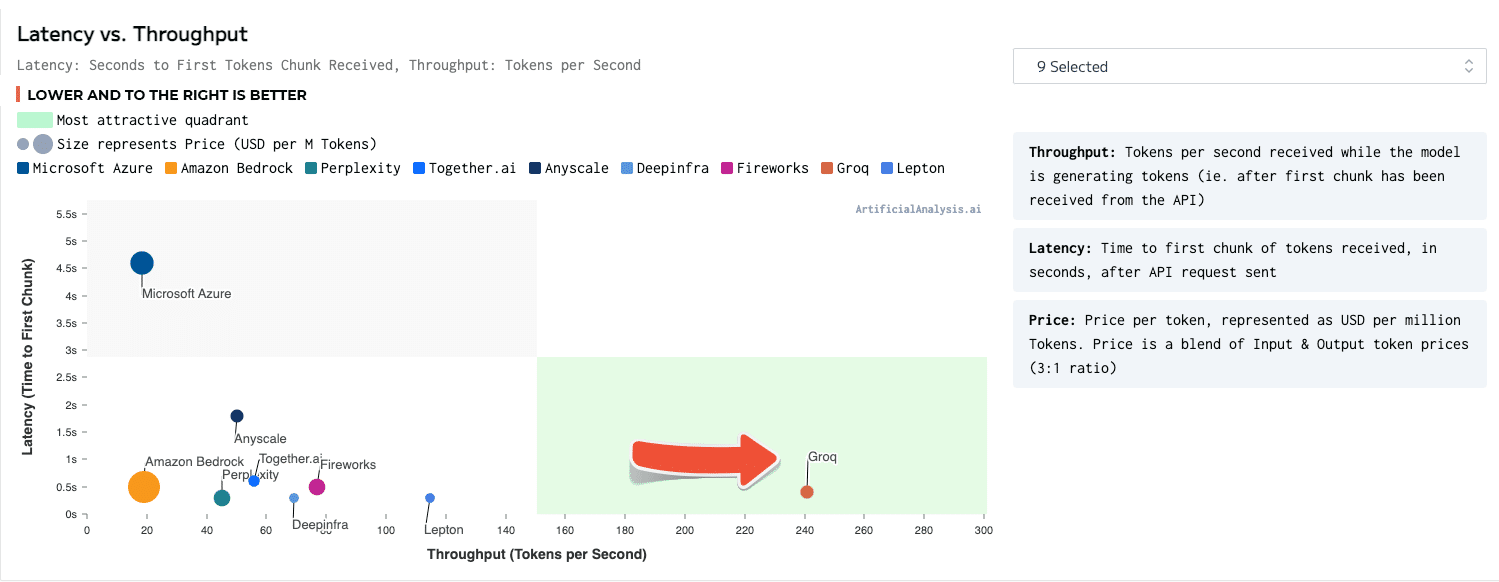
Descrizione
Un motore di inferenza LPU, con LPU in piedi per Language Processing Unit ™, è un nuovo tipo di sistema di unità di elaborazione end-to-end che fornisce l'inferenza più veloce a ~ 500 token/secondo.