Flashmla
Faster LLM Inference su Hopper GPUS
In Evidenza
5 Voti

Descrizione
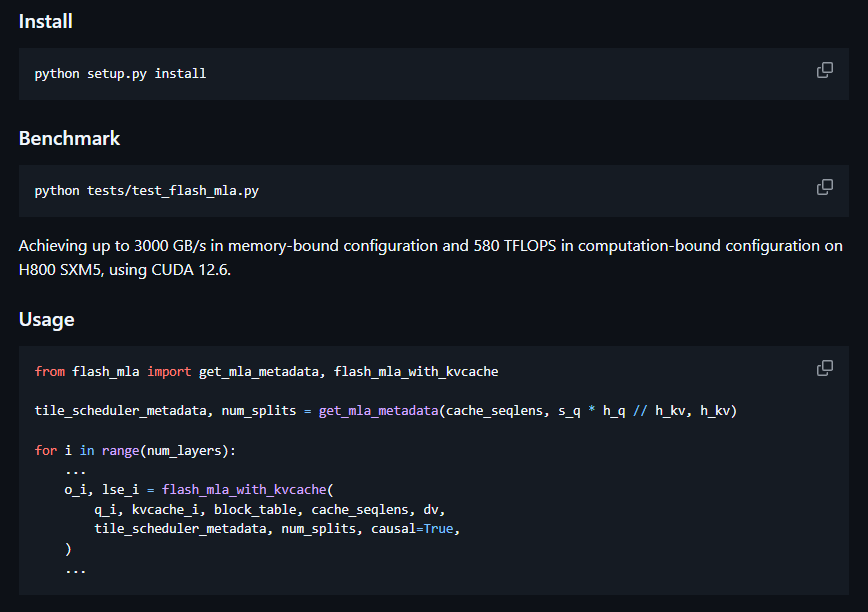
FlashMLA, di DeepSeek, è un efficiente kernel di decodifica MLA per GPU Hopper, ottimizzato per sequenze a lunghezza variabile.Raggiunge fino a 3000 GB/s di larghezza di banda di memoria e 580 TFLOP.