Vektor -Cache
Eine Python -Bibliothek für effizientes LLM -Abfrage -Caching
Empfohlen
23 Stimmen
Beschreibung
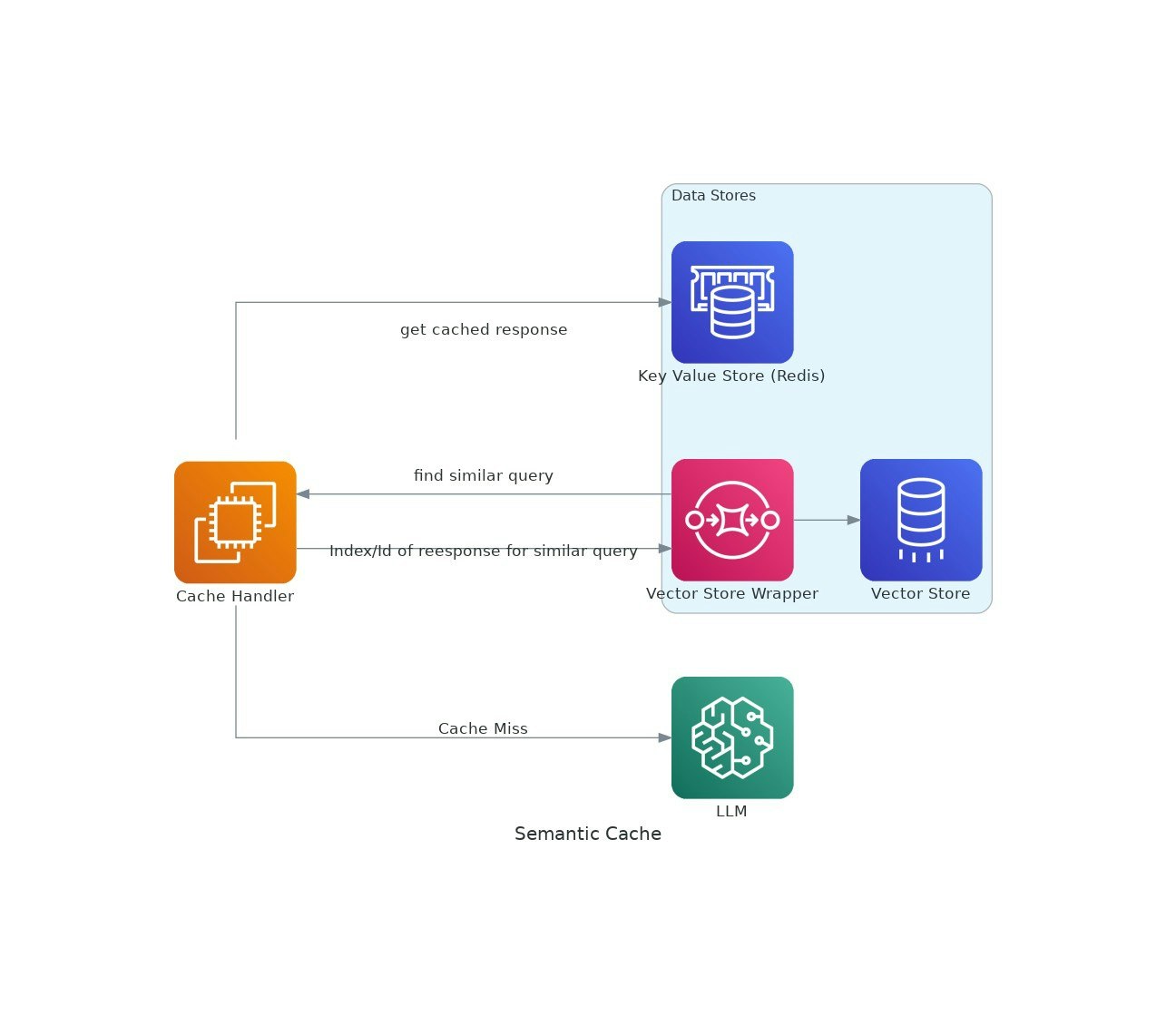
Wenn KI -Anwendungen an Traktion gewinnen, können die Kosten und die Latenz der Verwendung von LLM -Modellen (Language -Modellen) eskalieren.VectorCache befasst sich mit diesen Problemen, indem sie LLM -Antworten basierend auf semantischer Ähnlichkeit zwischen den Kosten und den Reaktionszeiten reduzieren.