ProductHubX
首頁
類別
標籤
部落格
最愛
提交
登入
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
繁體中文
登入
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
繁體中文
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
繁體中文
首頁
類別
標籤
部落格
最愛
提交
登入
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
繁體中文
首頁
類別
大型語言模型
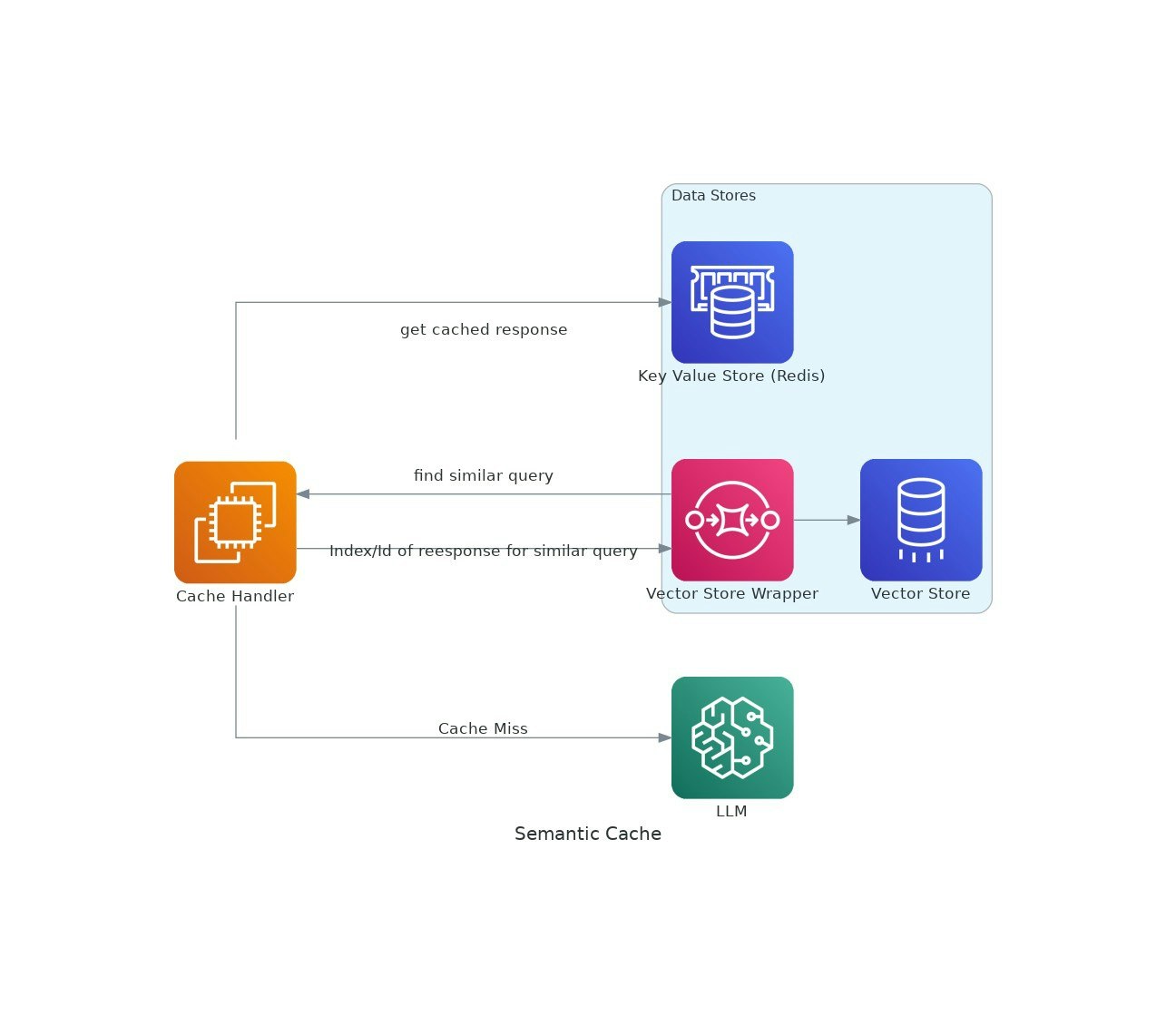
向量緩存
向量緩存
有效LLM查詢緩存的Python庫
特色
23 投票
訪問網站
描述
隨著AI應用程序的吸引力,使用大語言模型(LLM)的成本和延遲可能會升級。VectorCache通過基於語義相似性緩存LLM響應來解決這些問題,從而減少了成本和響應時間。
類別
大型語言模型
Git客戶端
標籤
軟件工程
開發人員工具
人工智慧
Girub
推薦產品
Install ProductHubX APP
該站點可以作為應用程序安裝。它將在自己的窗口中打開,並與OS功能安全地集成。
現在不要
安裝
Install ProductHubX APP
該站點可以作為應用程序安裝。它將在自己的窗口中打開,並與OS功能安全地集成。
現在不要
安裝