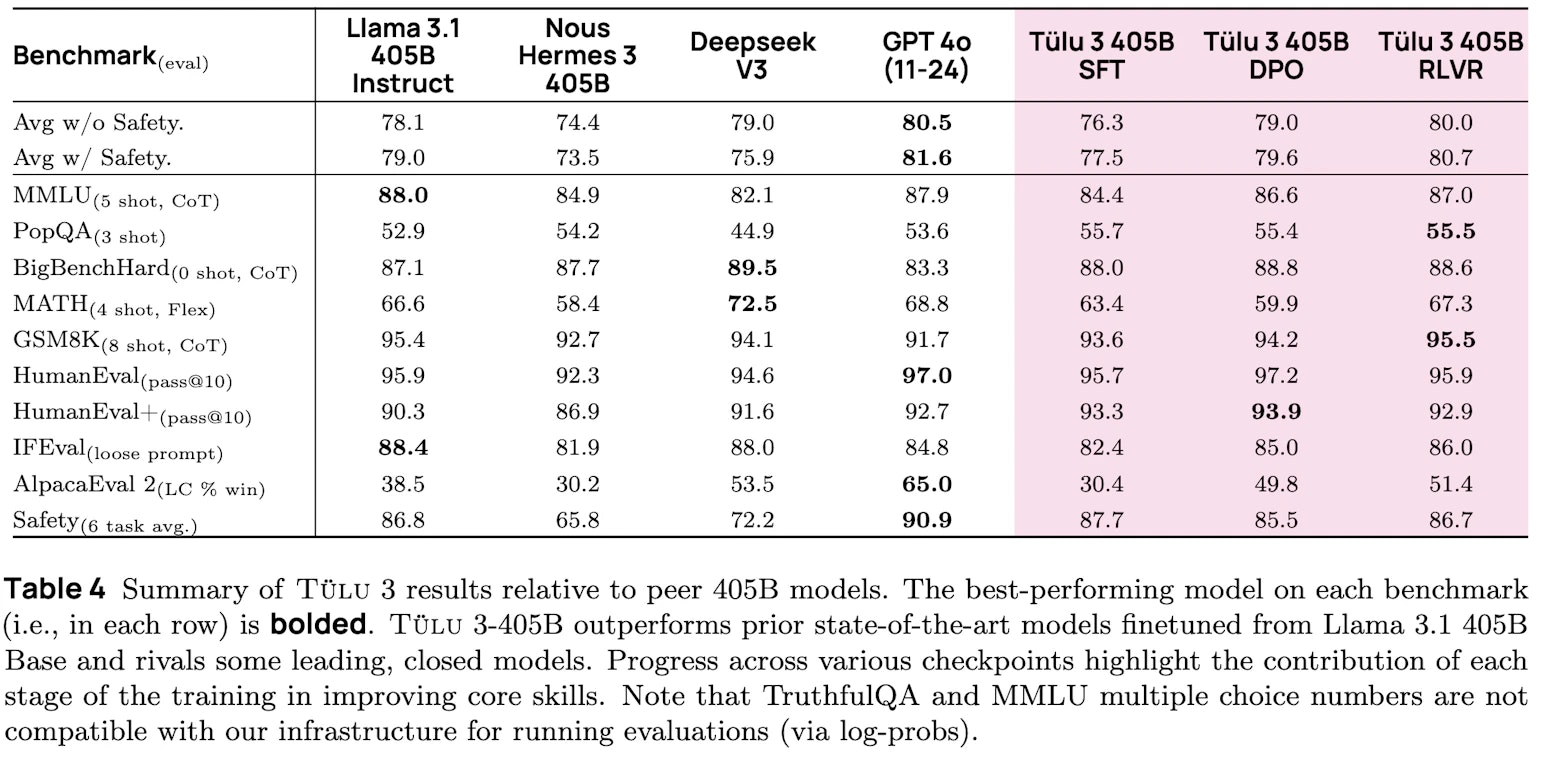
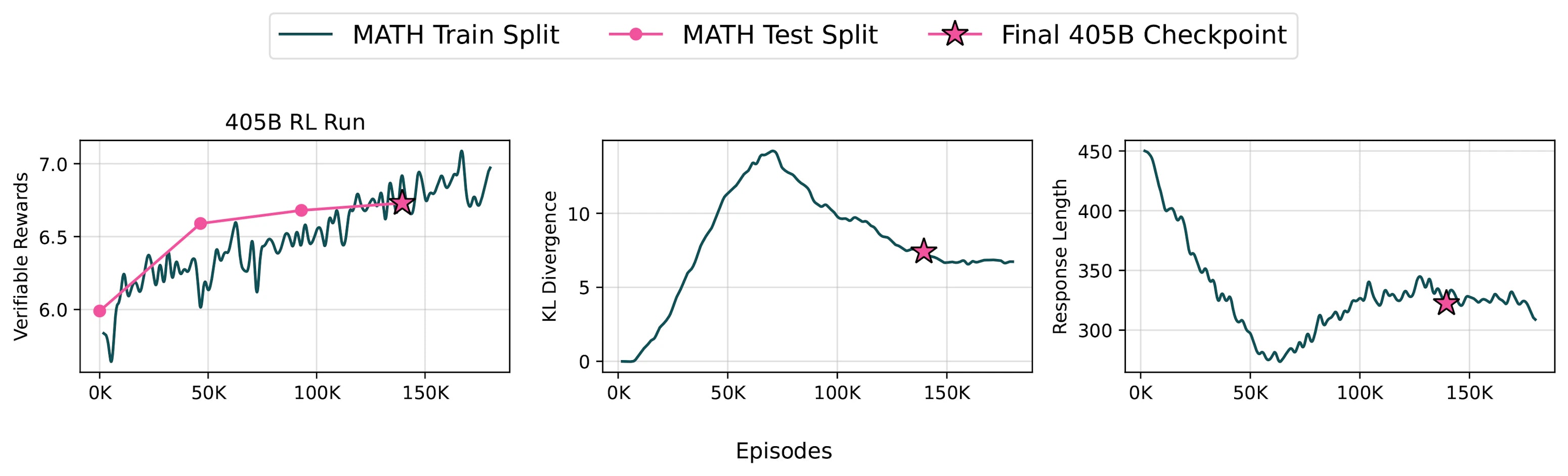
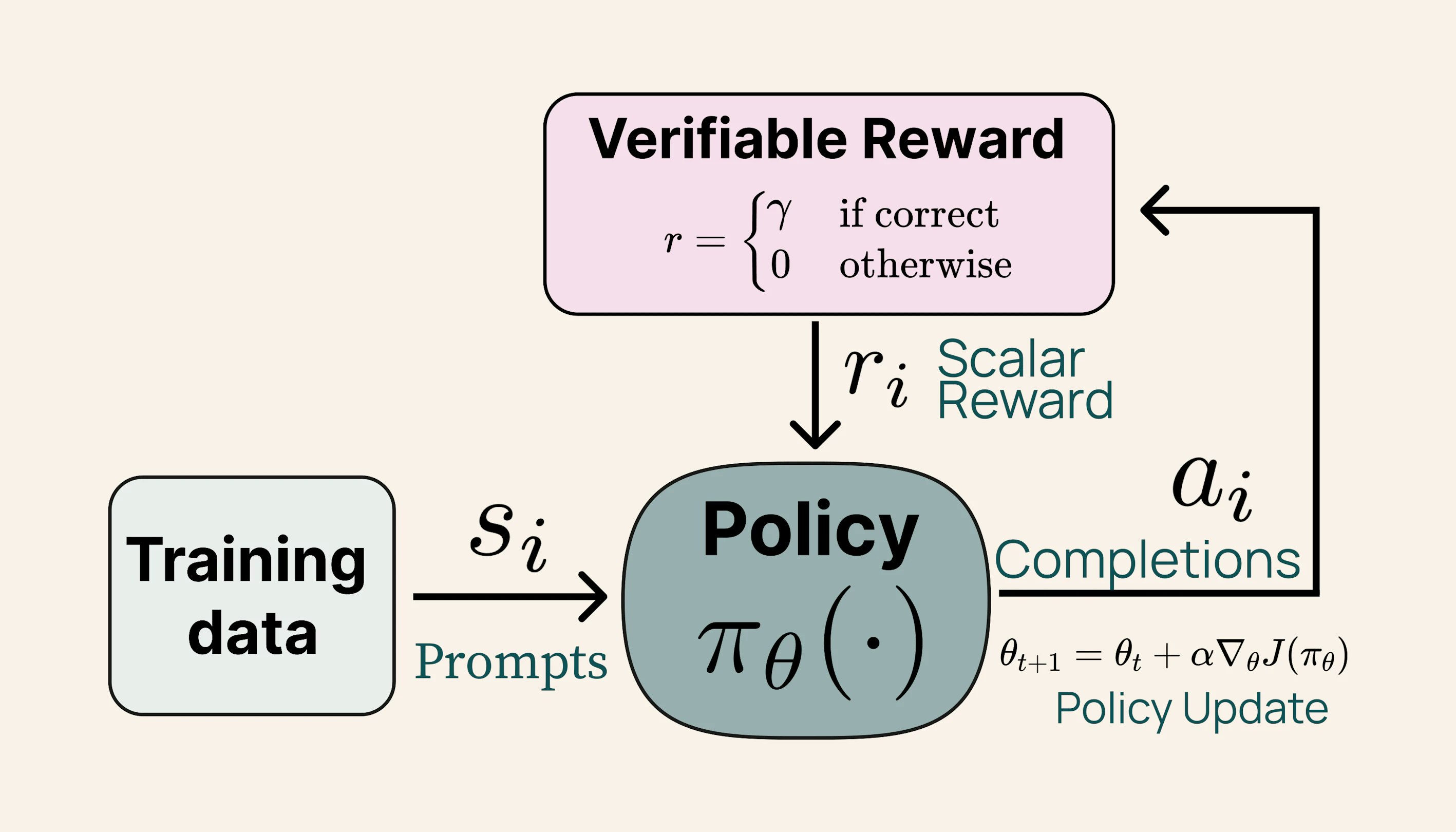
tülu3 405b,Tülu3系列中的最新表現,超過了DeepSeek-V3,與Llama 3.1(如Llama 3.1)相比,競爭對手GPT-4O和其他開放式訓練後培訓模型。利用可驗證獎勵(RVLR)學習的加強學習,將其擴展到405b參數,設置新的基準測試。