Bộ đệm vector
Thư viện Python cho bộ nhớ đệm truy vấn LLM hiệu quả
Đặc trưng
23 Phiếu bầu
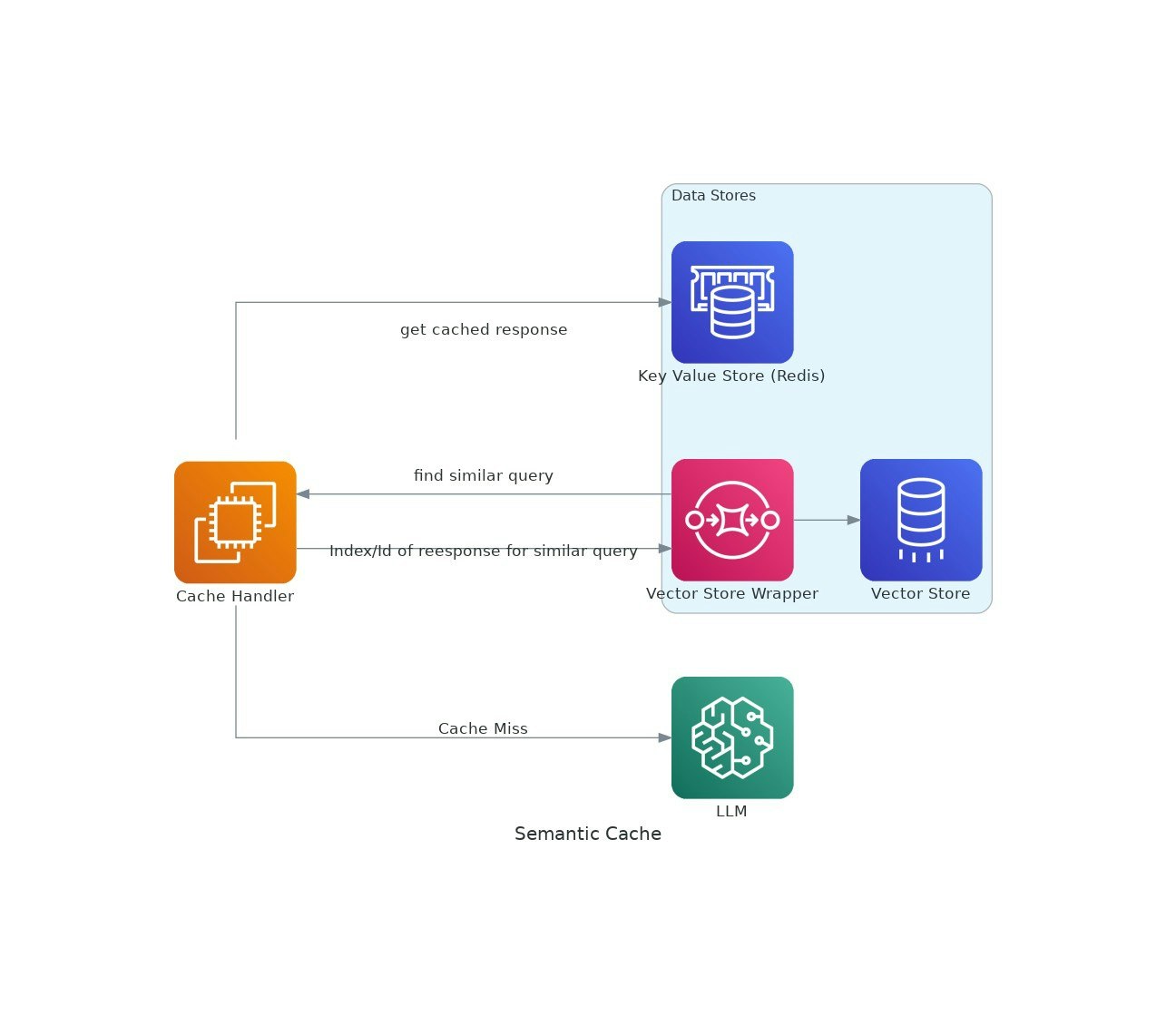
Sự miêu tả
Khi các ứng dụng AI đạt được lực kéo, chi phí và độ trễ của việc sử dụng các mô hình ngôn ngữ lớn (LLM) có thể leo thang.VectorCache giải quyết các vấn đề này bằng cách lưu bộ nhớ phản hồi LLM dựa trên sự tương đồng về ngữ nghĩa, do đó giảm cả chi phí và thời gian phản hồi.