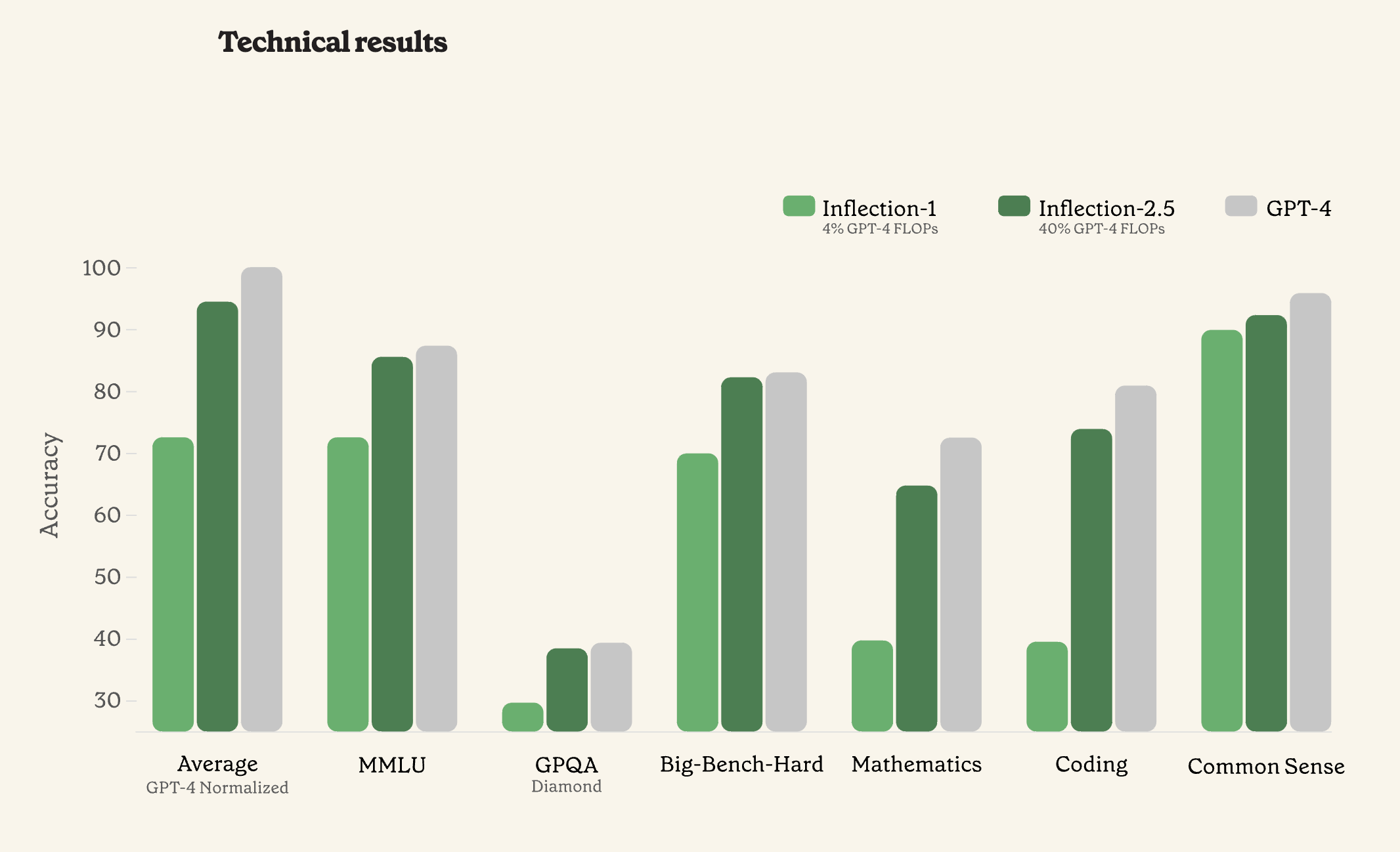
Biến kết-2.5
Hiệu suất gần GPT-4 trên 60% ít tính toán để đào tạo
Nổi Bật
149 Bình Chọn
Thịnh Hành
116 Lượt Xem

Mô Tả
Kích hoạt-2.5 tiếp cận hiệu suất của GPT-4, nhưng chỉ sử dụng 40% lượng tính toán để đào tạo. Nó kết hợp khả năng thô với tính cách đặc trưng của sự thay đổi và tinh chỉnh đồng cảm độc đáo.