Векторный кеш
Библиотека Python для эффективного кэширования запросов LLM
Рекомендуемые
23 Голоса
Описание
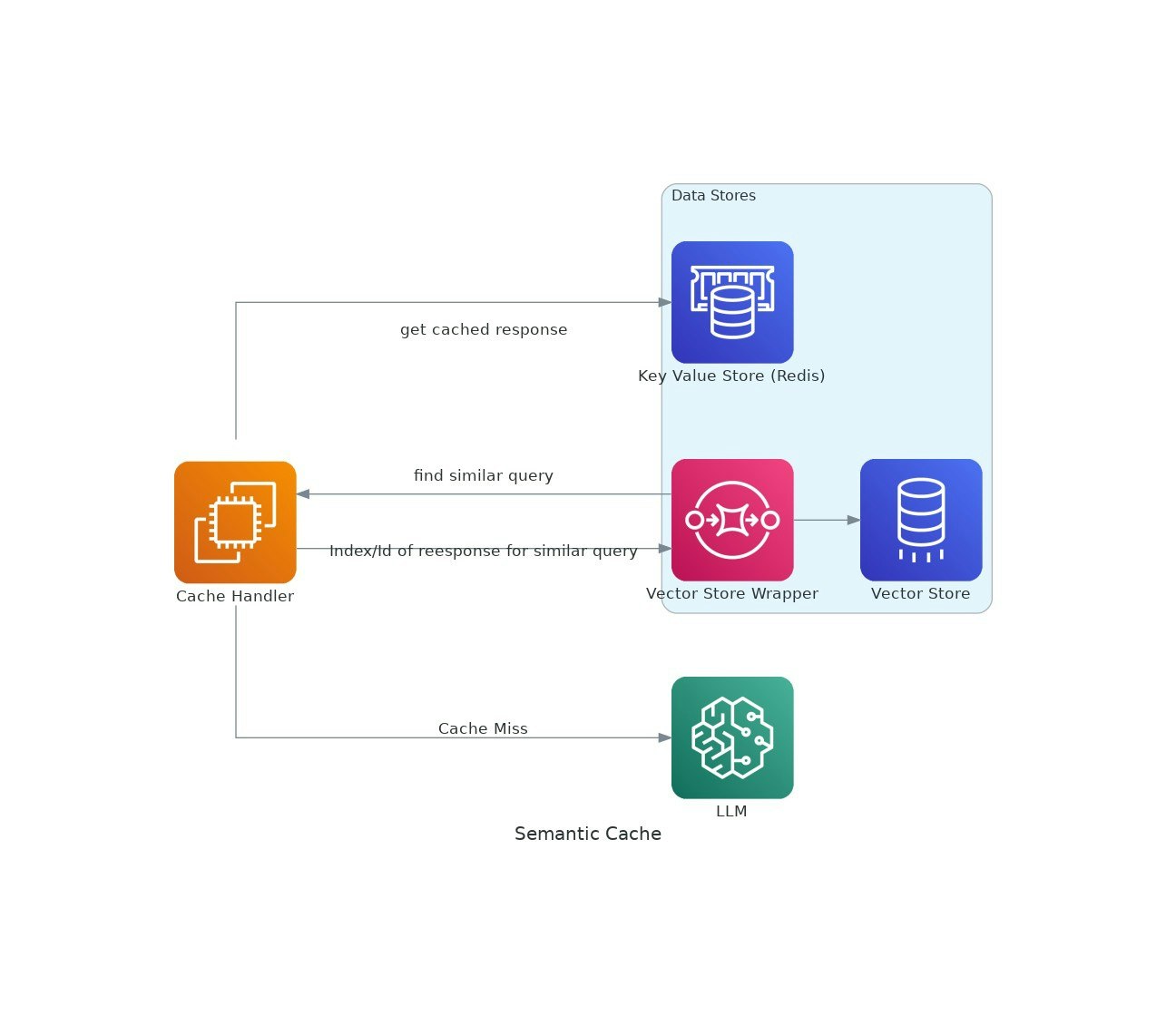
Поскольку приложения AI получают тягу, затраты и задержка использования крупных языковых моделей (LLMS) могут обостриться.VectorCache решает эти проблемы, кэшируя ответы LLM на основе семантического сходства, тем самым снижая как затраты, так и время отклика.