Vector Cache
A Python Library for Efficient LLM Query Caching
Featured
23 Votes
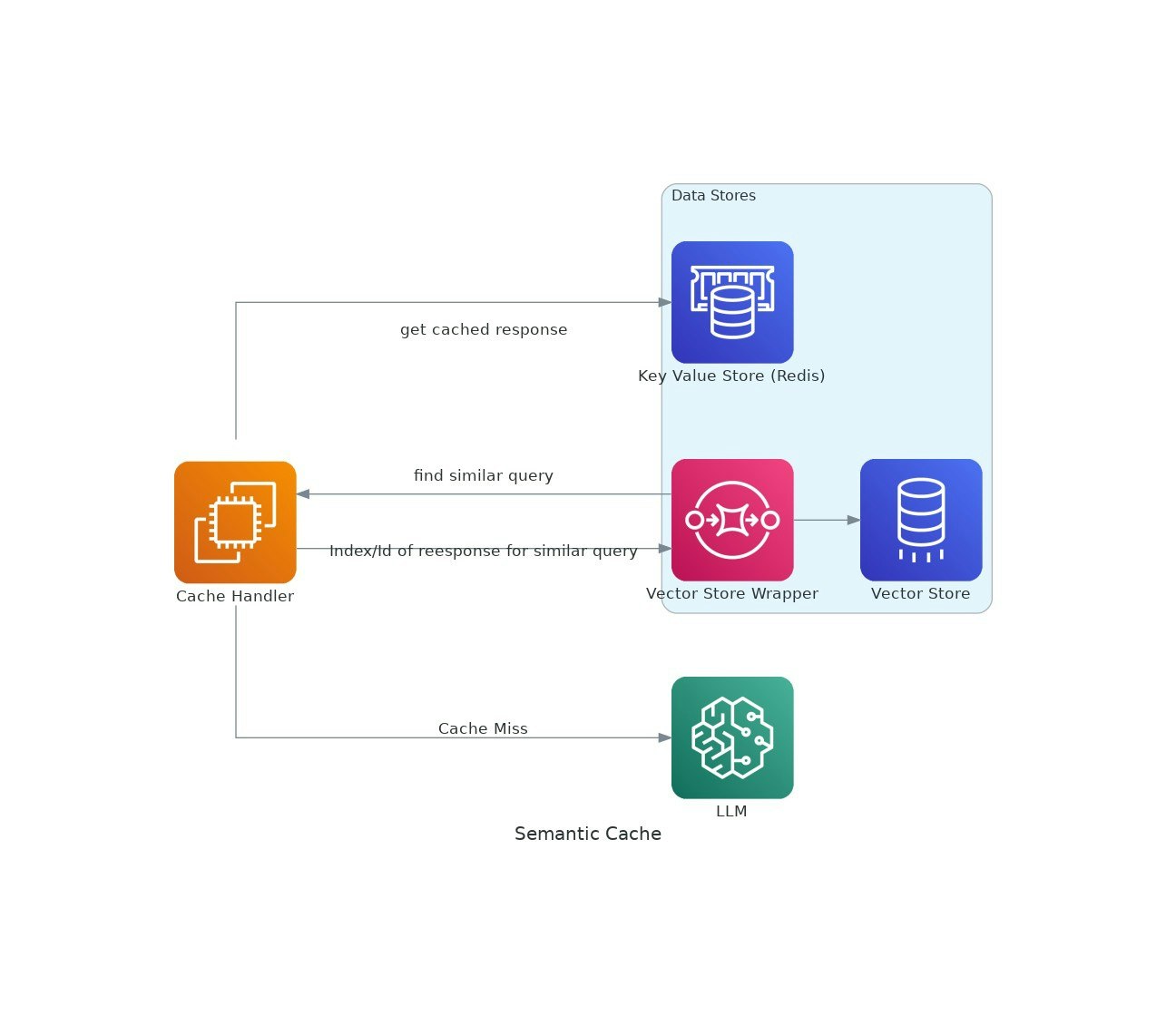
Description
As AI applications gain traction, the costs and latency of using large language models (LLMs) can escalate. VectorCache addresses these issues by caching LLM responses based on semantic similarity, thereby reducing both costs and response times.