Cache vektor
Perpustakaan Python untuk caching pertanyaan LLM yang cekap
Pilihan
23 Undi
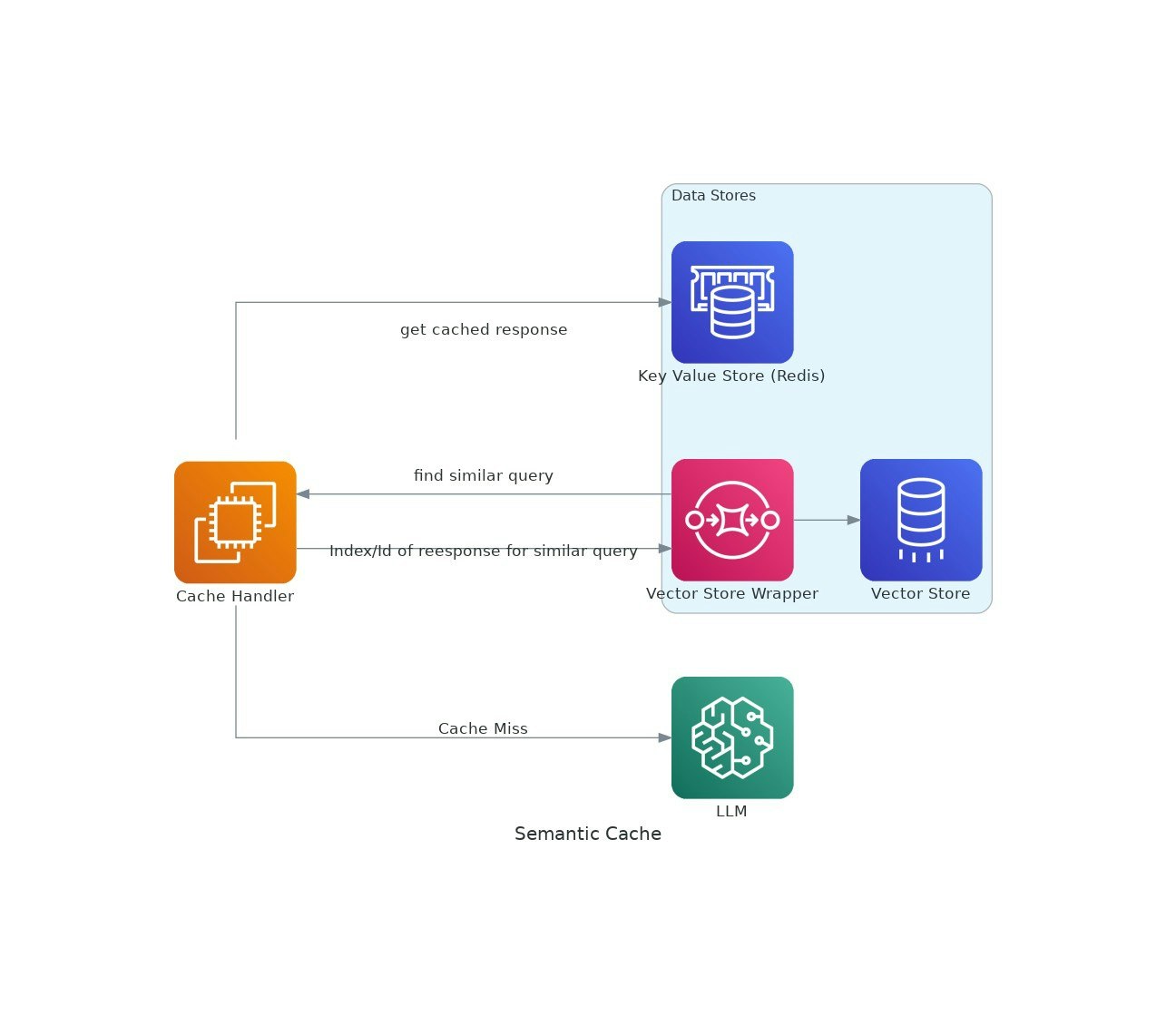
Penerangan
Oleh kerana aplikasi AI mendapat daya tarikan, kos dan latensi menggunakan model bahasa besar (LLMs) dapat meningkat.VectorCache menangani isu -isu ini dengan memberi respons LLM berdasarkan persamaan semantik, dengan itu mengurangkan kedua -dua kos dan masa tindak balas.