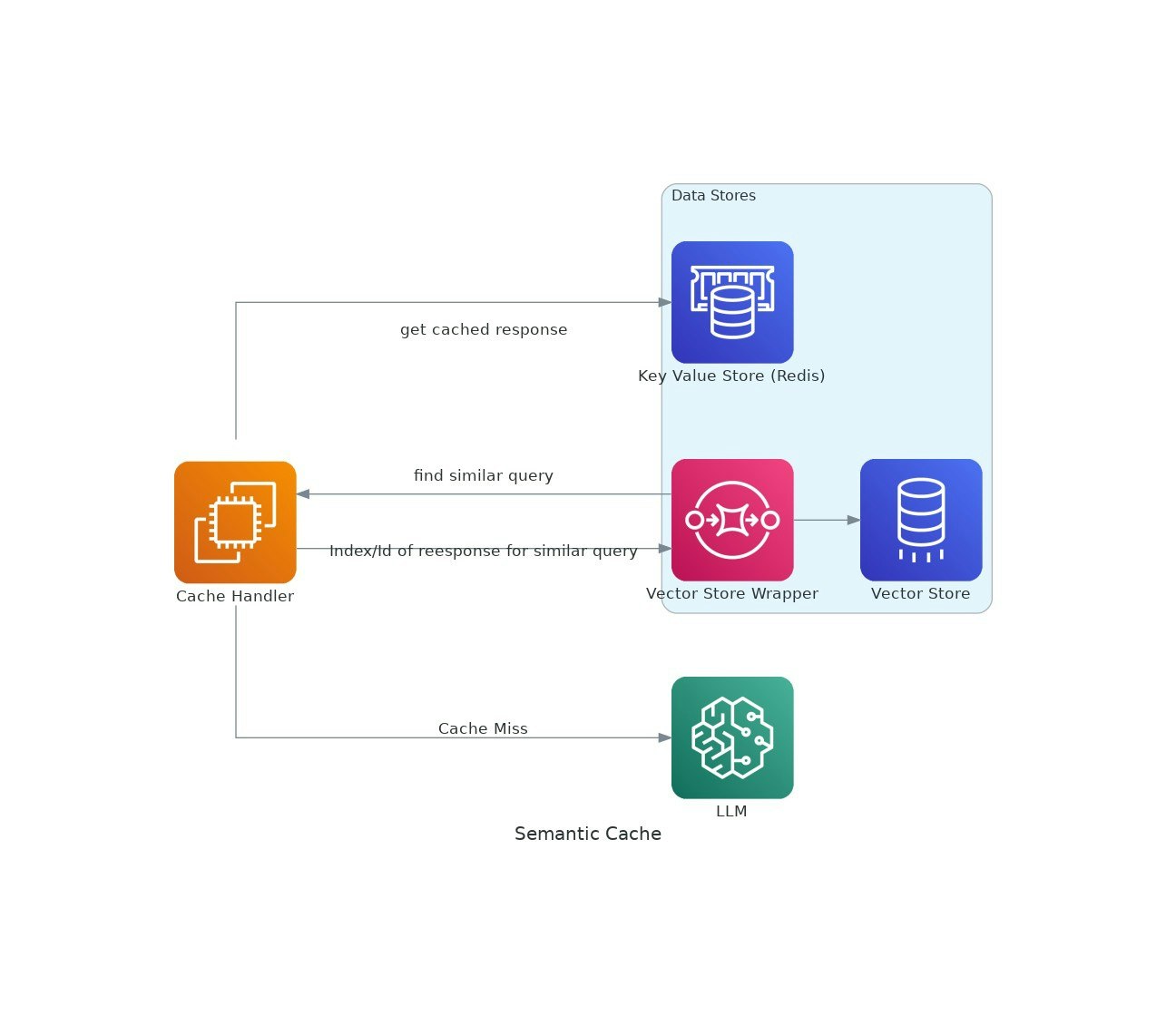
AI 애플리케이션이 트랙션을 얻음에 따라 LLM (Lange Language Model) 사용 비용과 대기 시간은 에스컬레이션 될 수 있습니다.VectorCache는 시맨틱 유사성에 기초하여 LLM 응답을 캐싱하여 이러한 문제를 해결하여 비용과 응답 시간을 모두 줄입니다.