ProductHubX
홈
카테고리
태그
블로그
즐겨찾기
제출
로그인
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
한국어
로그인
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
한국어
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
한국어
홈
카테고리
태그
블로그
즐겨찾기
제출
로그인
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
한국어
홈
카테고리
대규모 언어 모델
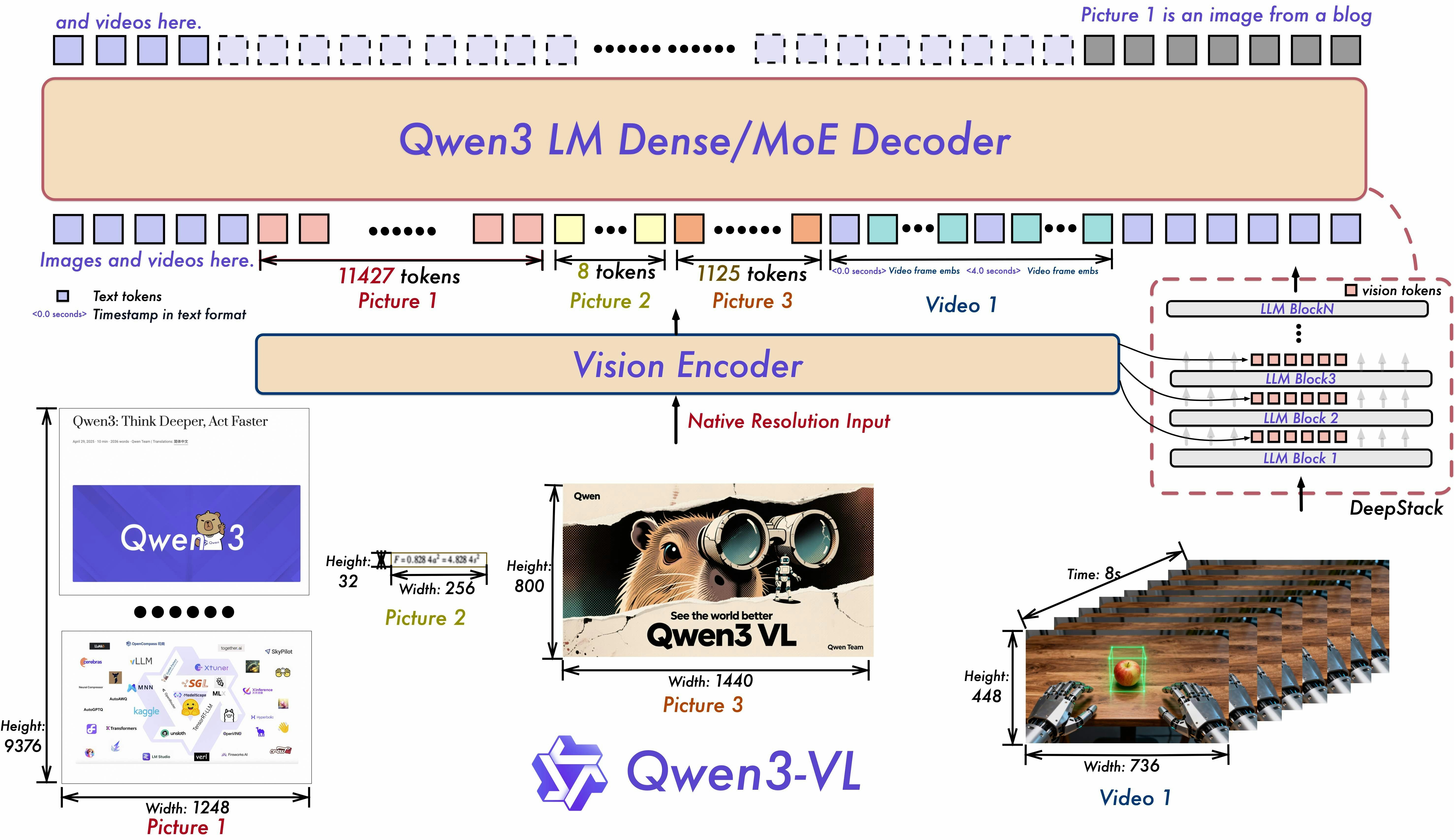
QWEN3-VL
QWEN3-VL
더 선명한 비전, 깊은 생각, 더 넓은 행동
추천
18 투표
웹사이트 방문
설명
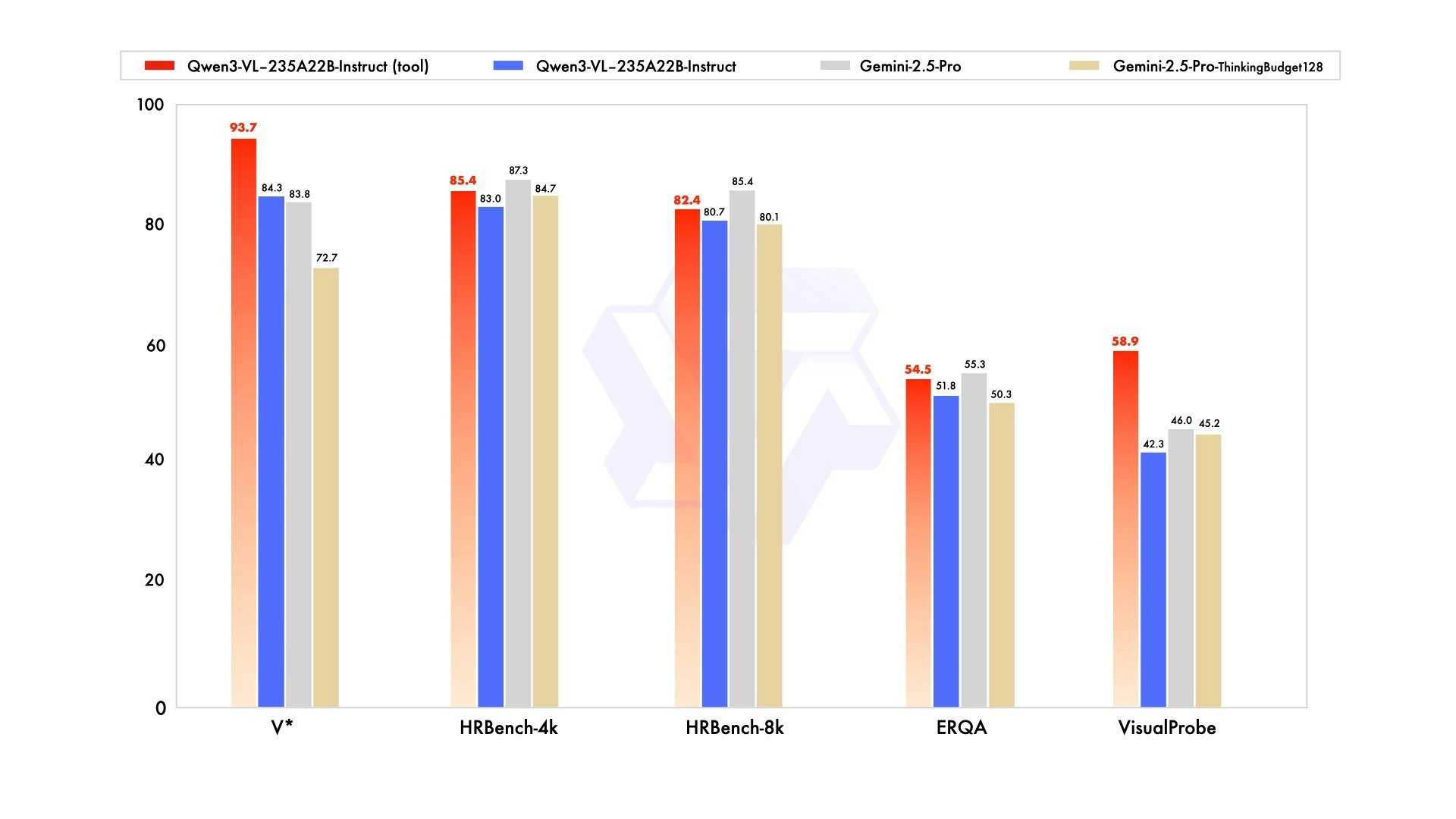
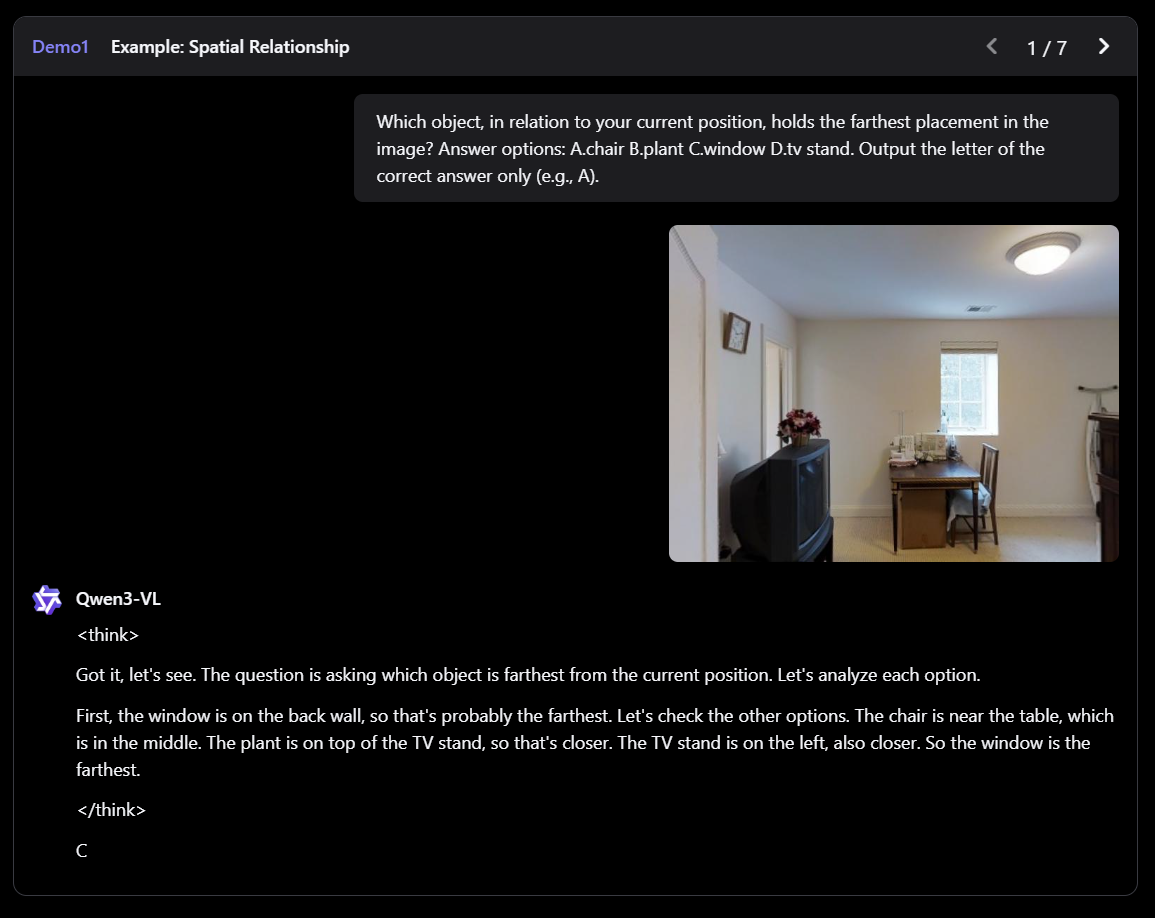
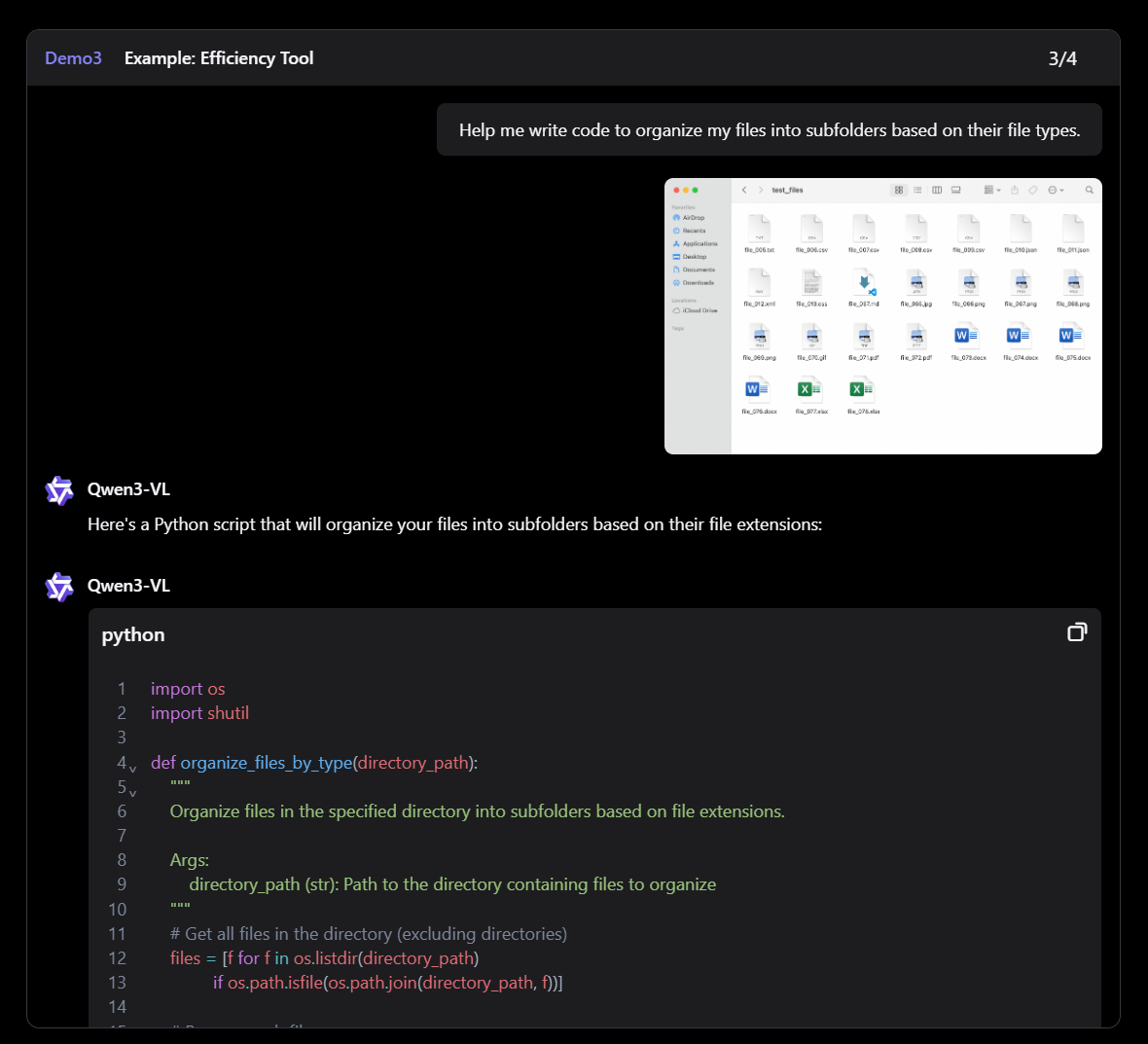
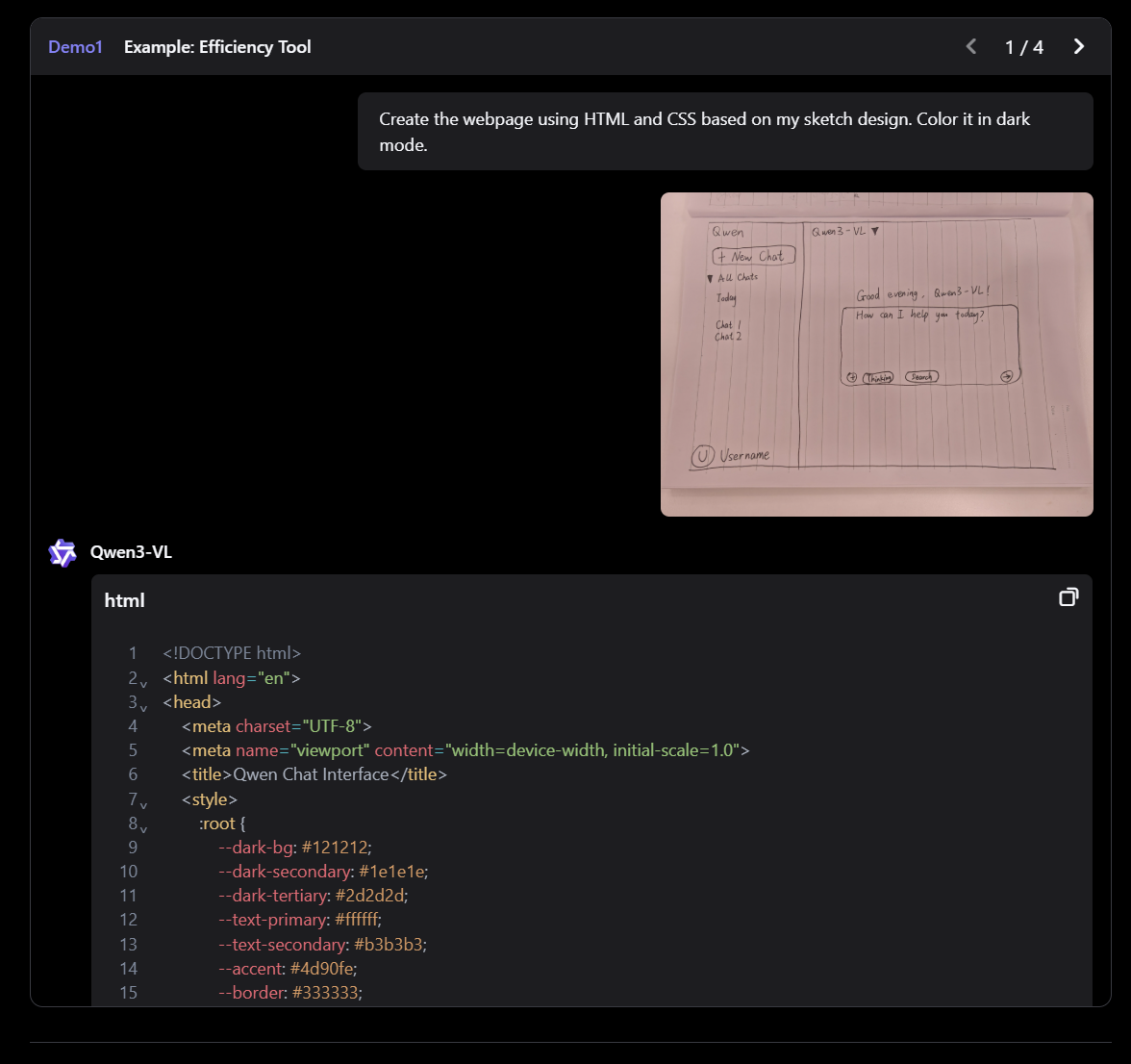
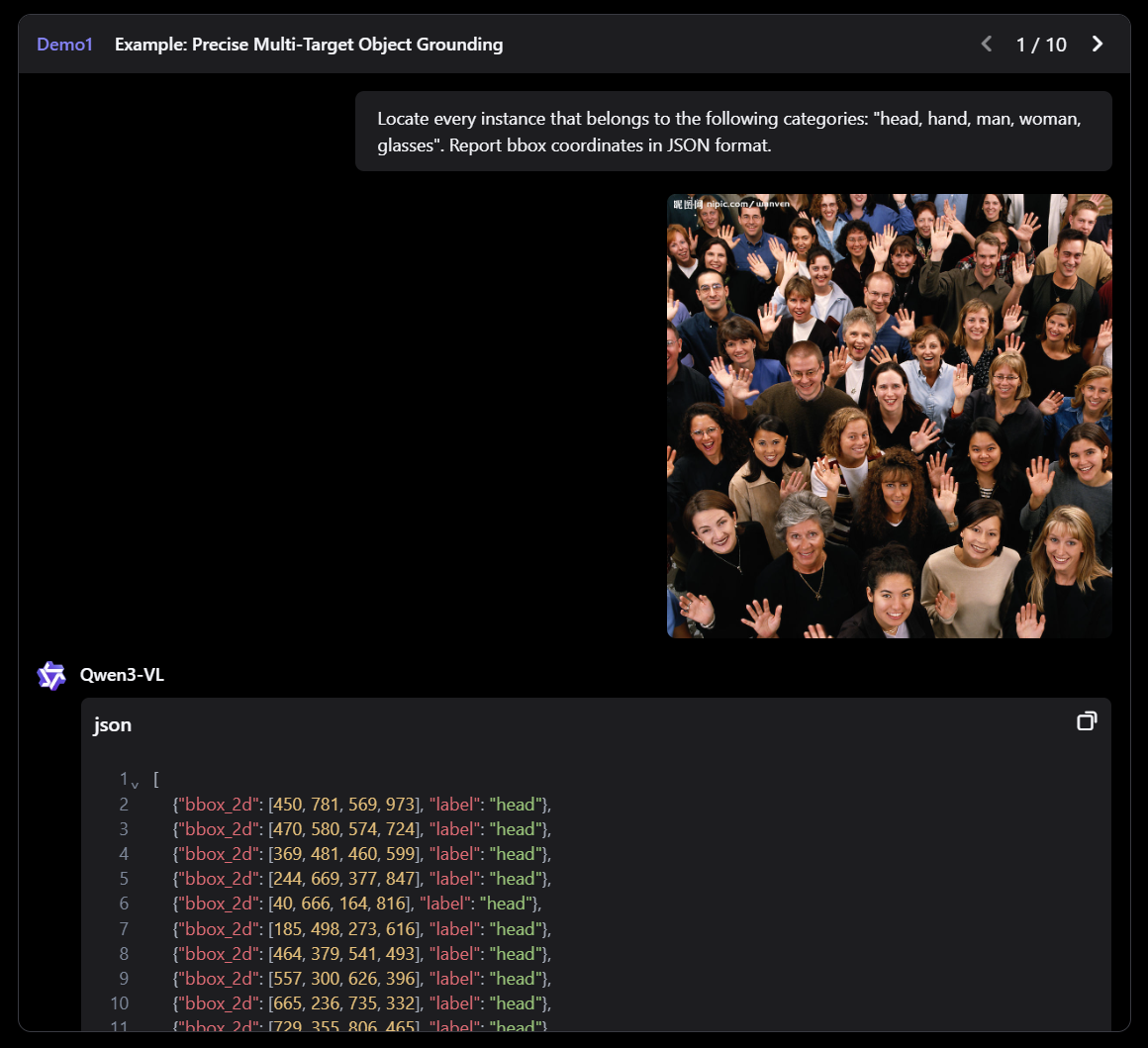
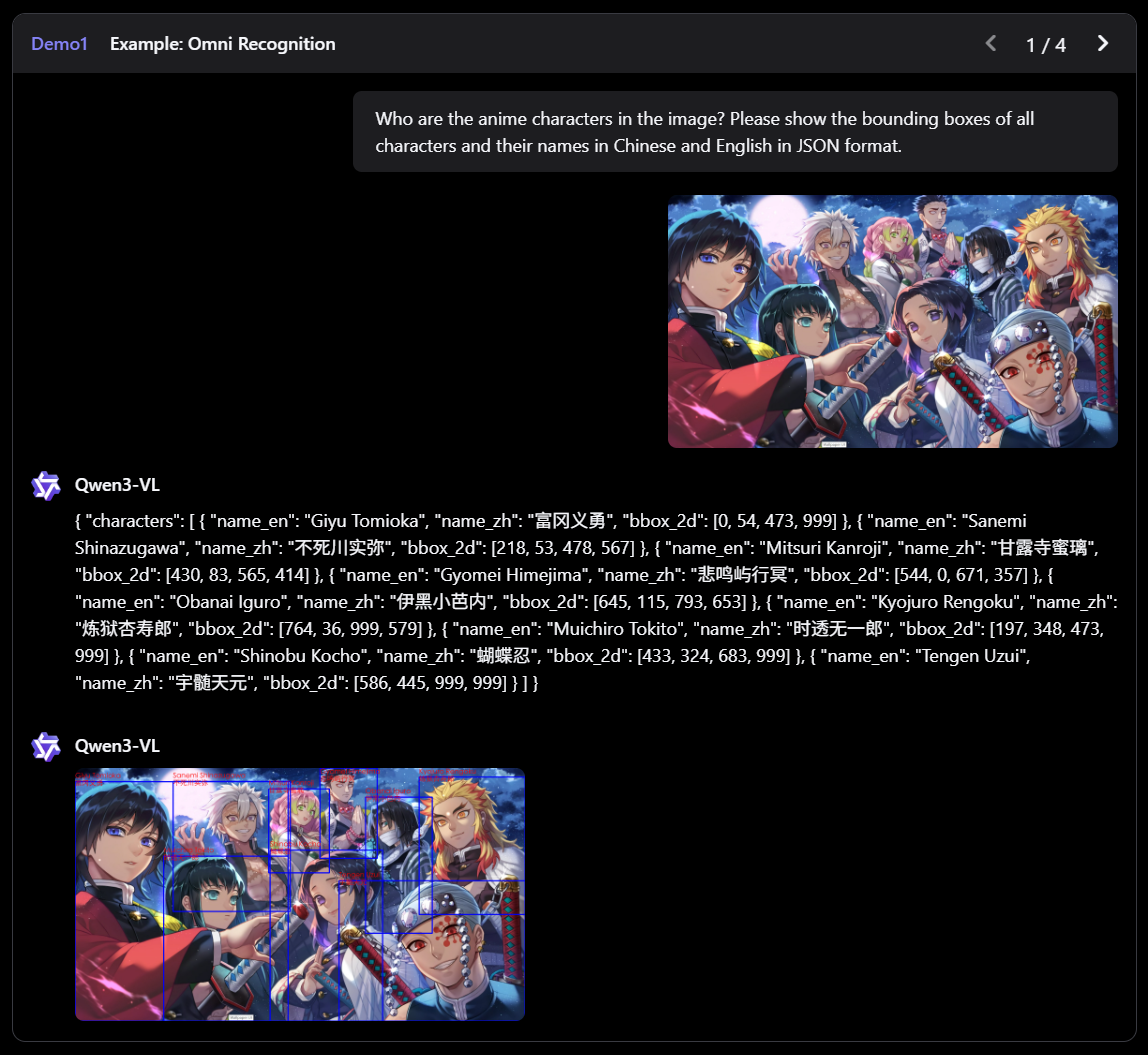
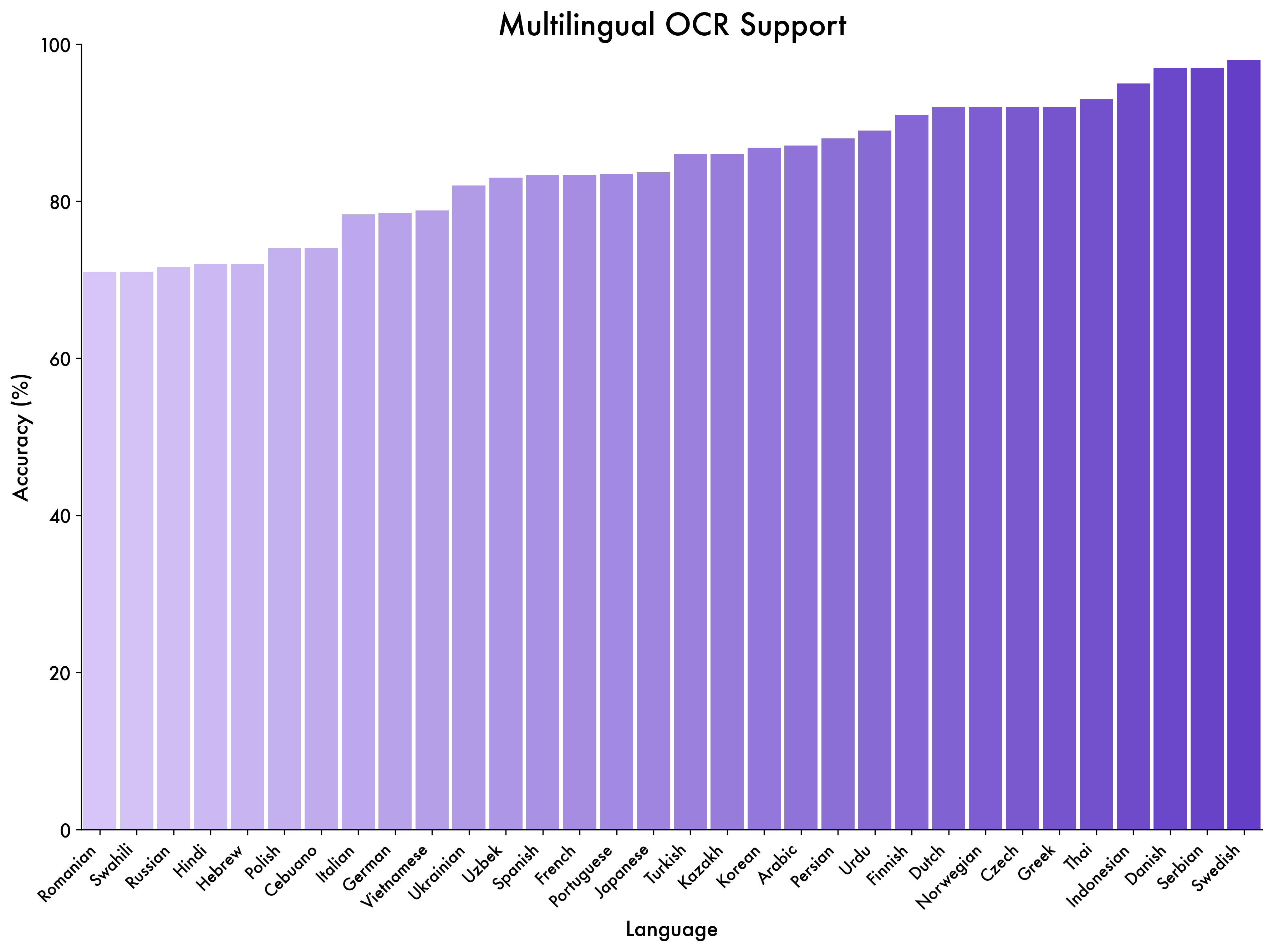
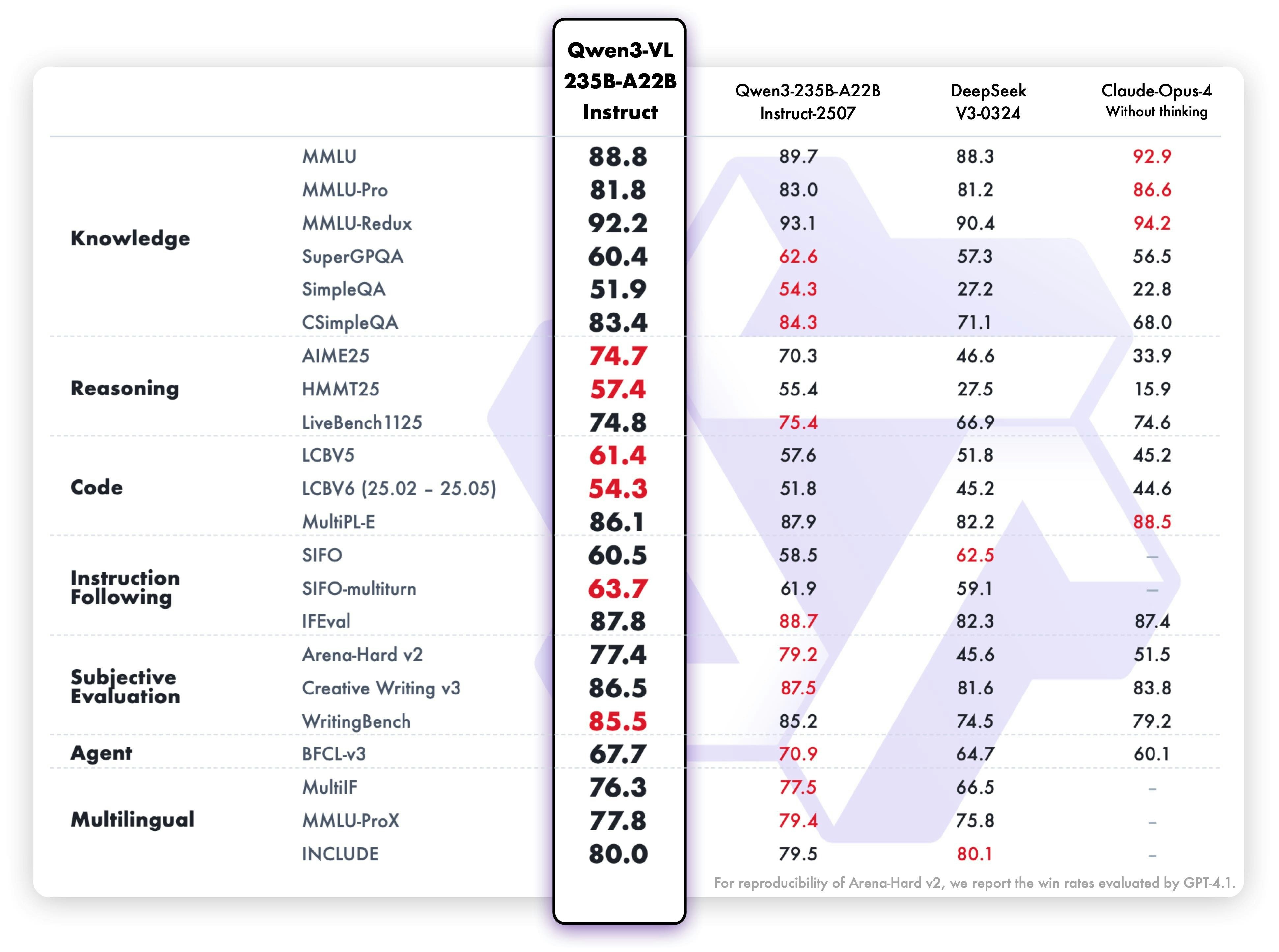
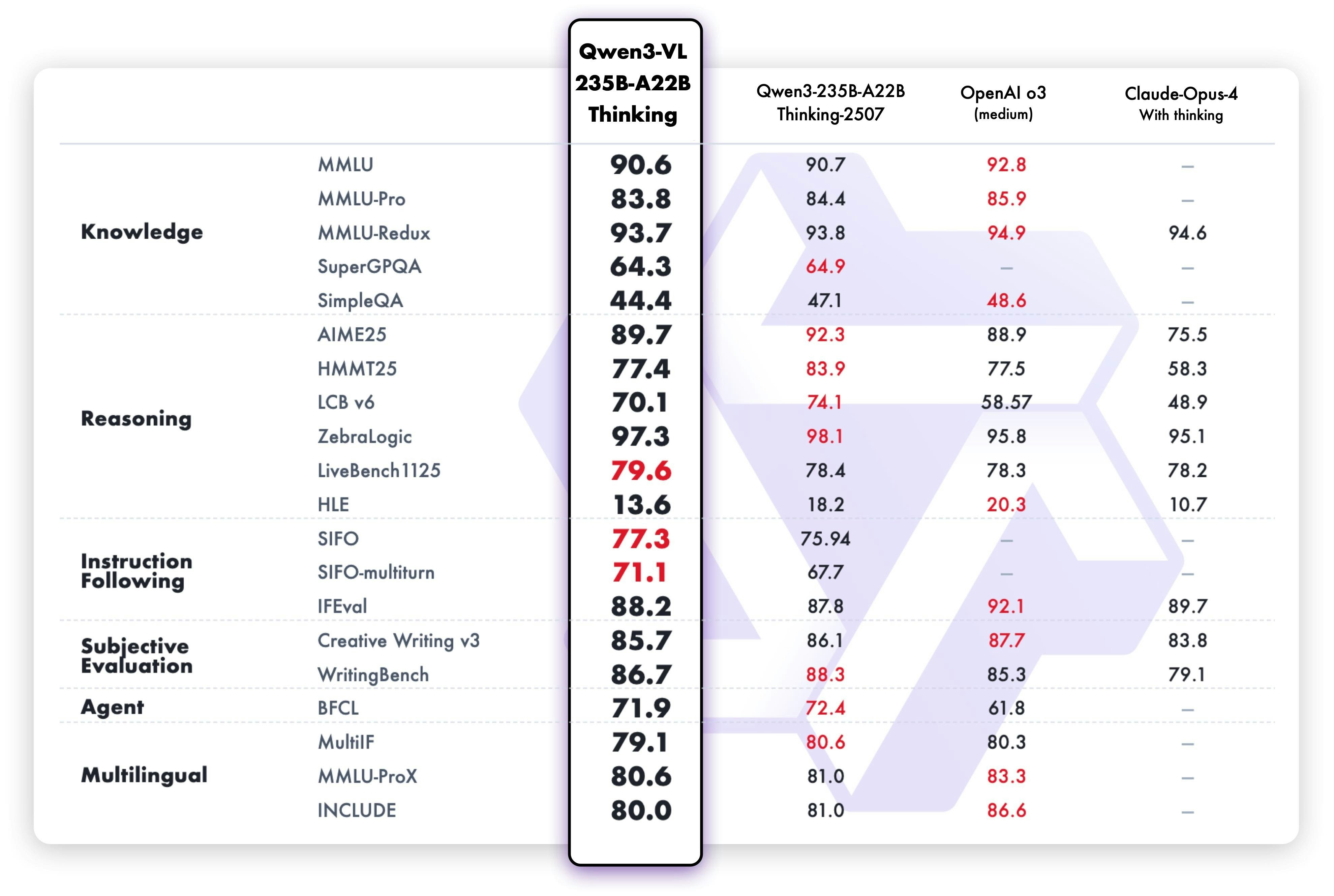
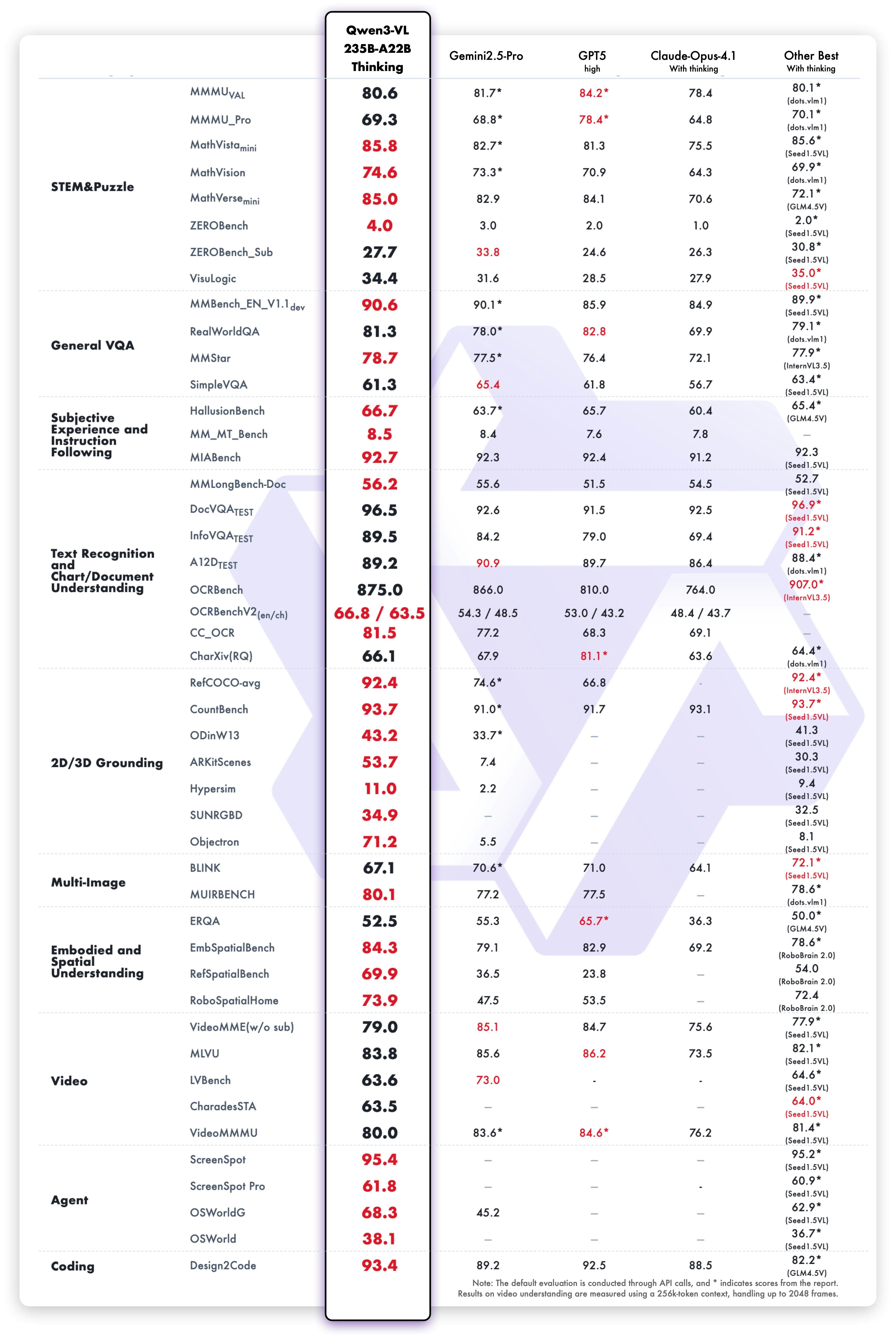
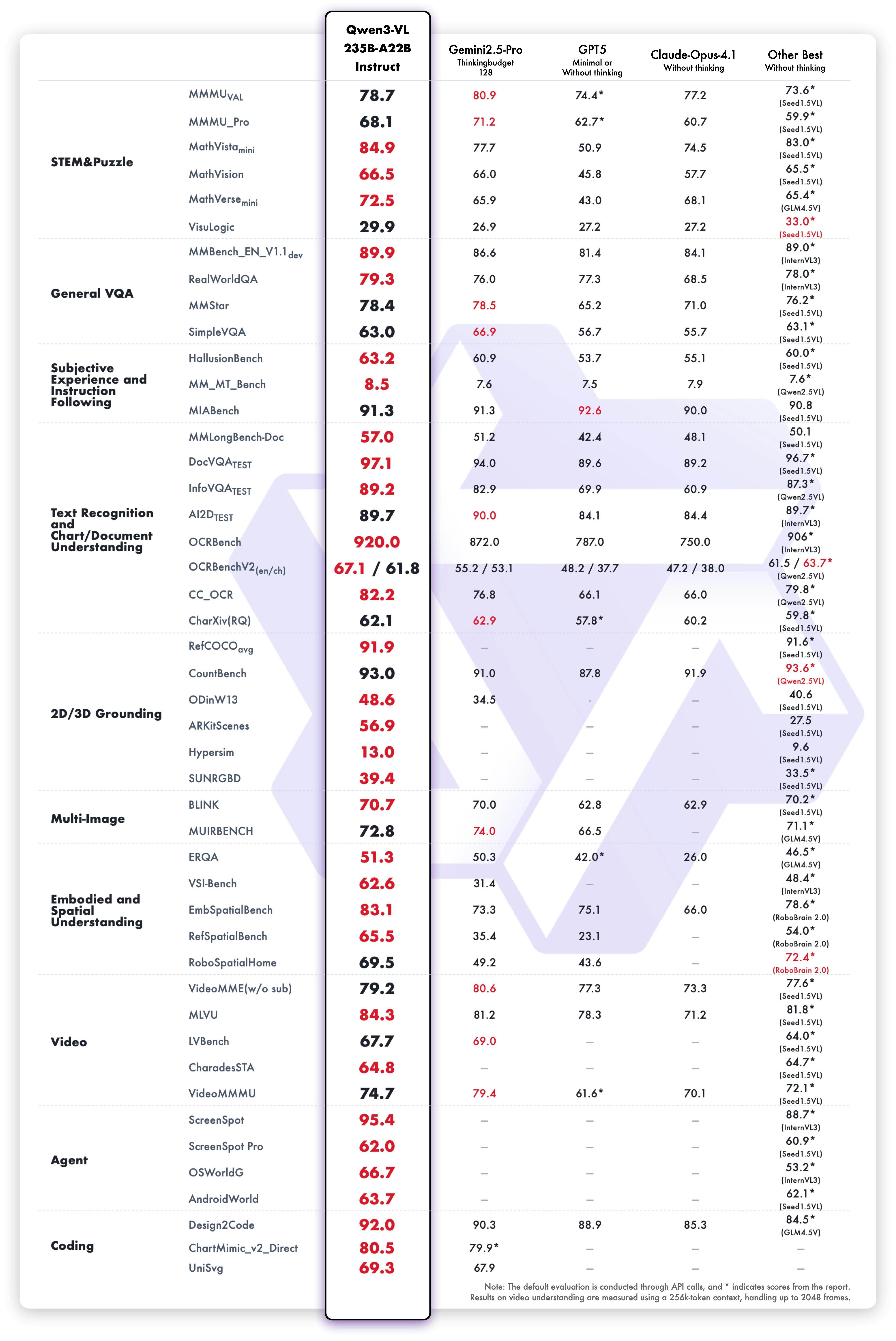
QWEN3-VL은 Qwen 팀의 새로운 플래그십 비전 언어 모델로, 시각적 에이전트 작업, 장기 비디오 이해 및 기본 256K 컨텍스트 창을 사용한 공간 추론에 뛰어납니다.
카테고리
대규모 언어 모델
코드 에디터
태그
오픈 소스
인공 지능
사진 및 비디오
추천 제품
ProductHubX 앱 설치
이 사이트는 애플리케이션으로 설치할 수 있습니다. 자체 창에서 열리고 OS 기능과 안전하게 통합됩니다.
지금은 아니요
설치
ProductHubX 앱 설치
이 사이트는 애플리케이션으로 설치할 수 있습니다. 자체 창에서 열리고 OS 기능과 안전하게 통합됩니다.
지금은 아니요
설치