모델레드
당신의 AI는 취약합니다.우리는 그것을 증명할 것입니다.
설명
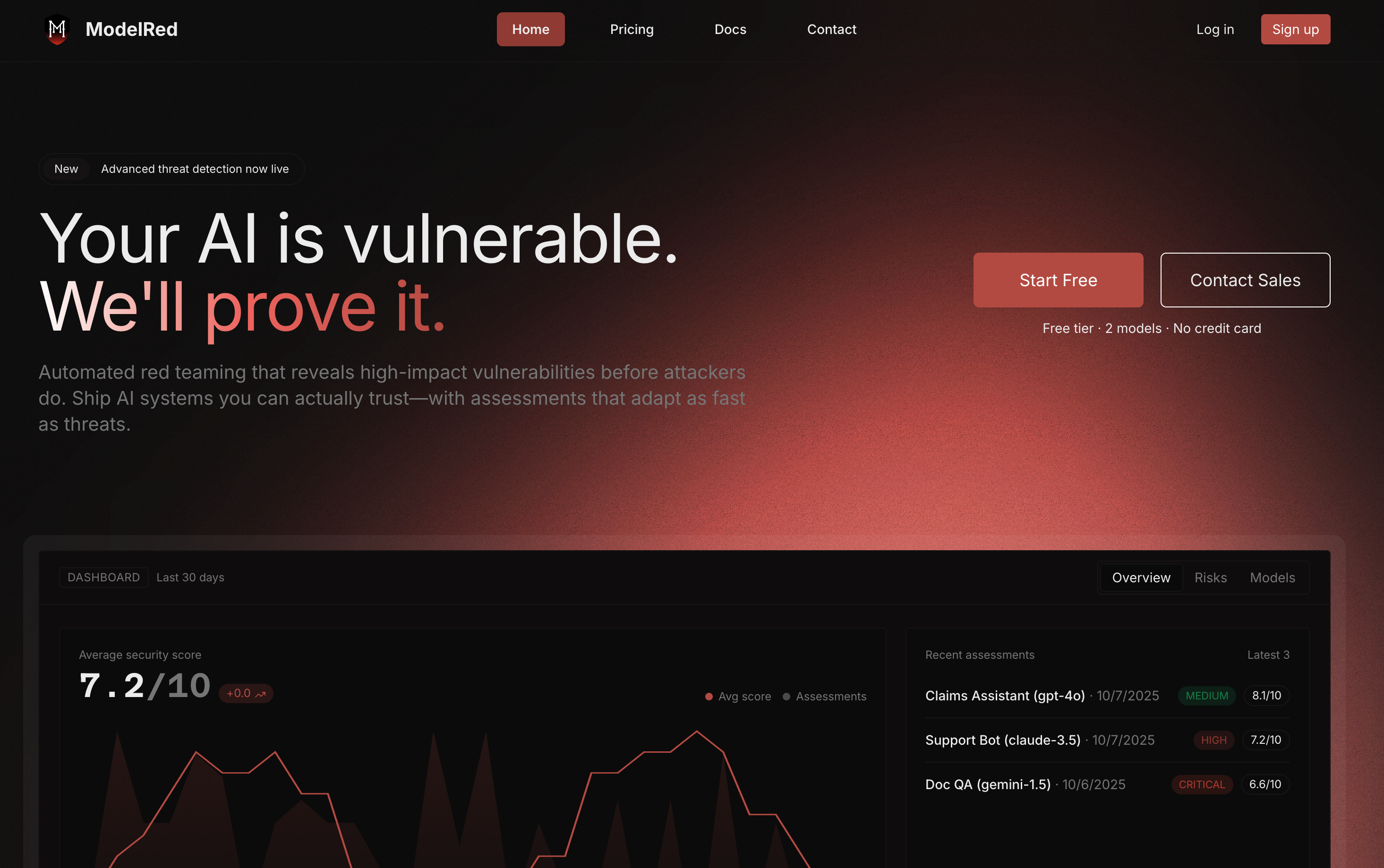
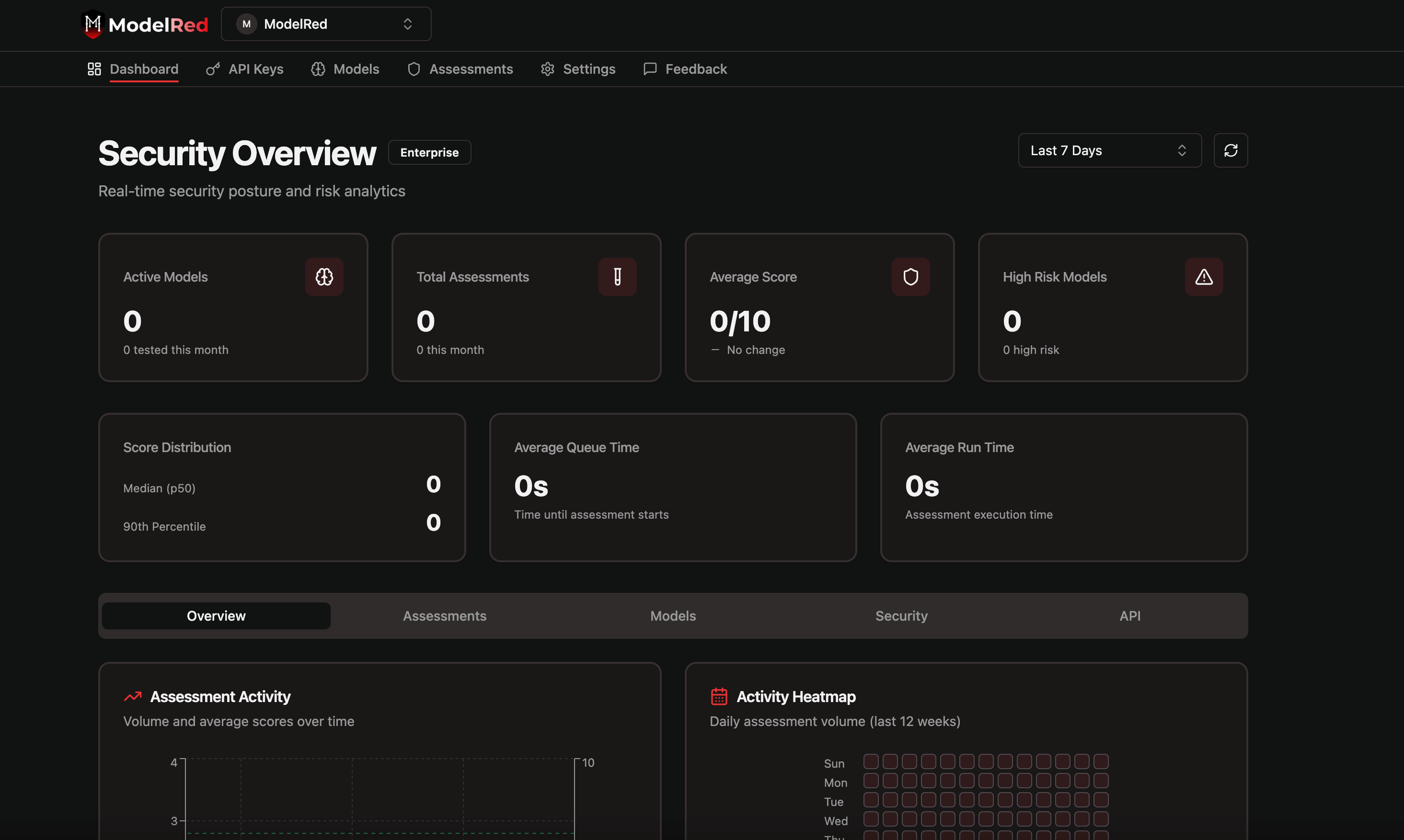
공격자가 발견하기 전에 AI 모델의 취약점을 자동으로 찾아냅니다.LLM, OpenAI, Anthropic, Azure, AWS, HuggingFace 등에서 4,000개의 공격 벡터를 테스트하는 200개의 적응형 레드팀 프로브를 실행하세요.ModelRed 점수를 얻고 안전한 AI를 더 빠르게 출시하세요.
공격자가 발견하기 전에 AI 모델의 취약점을 자동으로 찾아냅니다.LLM, OpenAI, Anthropic, Azure, AWS, HuggingFace 등에서 4,000개의 공격 벡터를 테스트하는 200개의 적응형 레드팀 프로브를 실행하세요.ModelRed 점수를 얻고 안전한 AI를 더 빠르게 출시하세요.