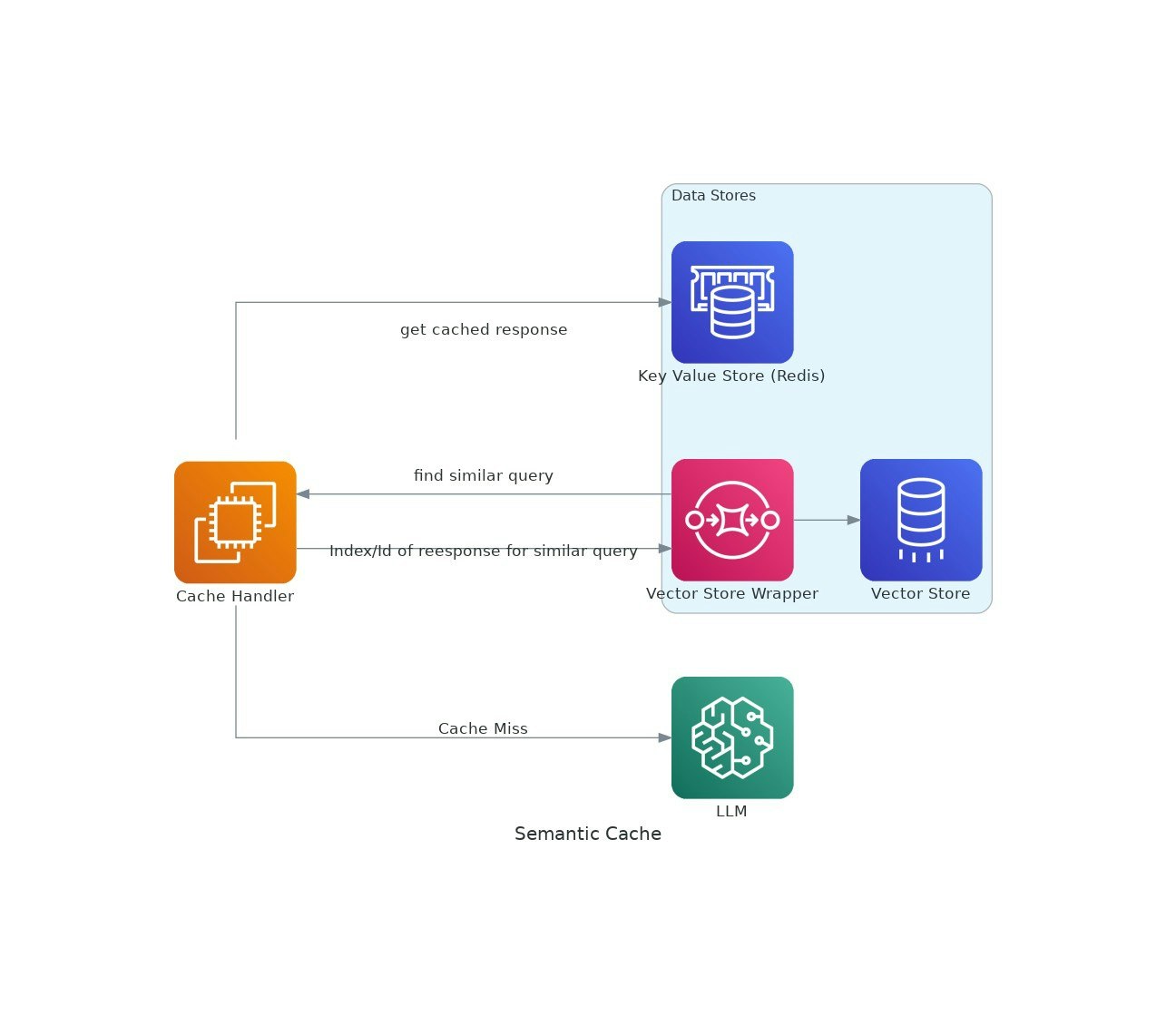
AIアプリケーションが牽引力を獲得するにつれて、大規模な言語モデル(LLM)を使用するコストと待ち時間がエスカレートする可能性があります。VectorCacheは、セマンティックの類似性に基づいてLLM応答をキャッシュすることにより、これらの問題に対処し、それによりコストと応答時間の両方を削減します。