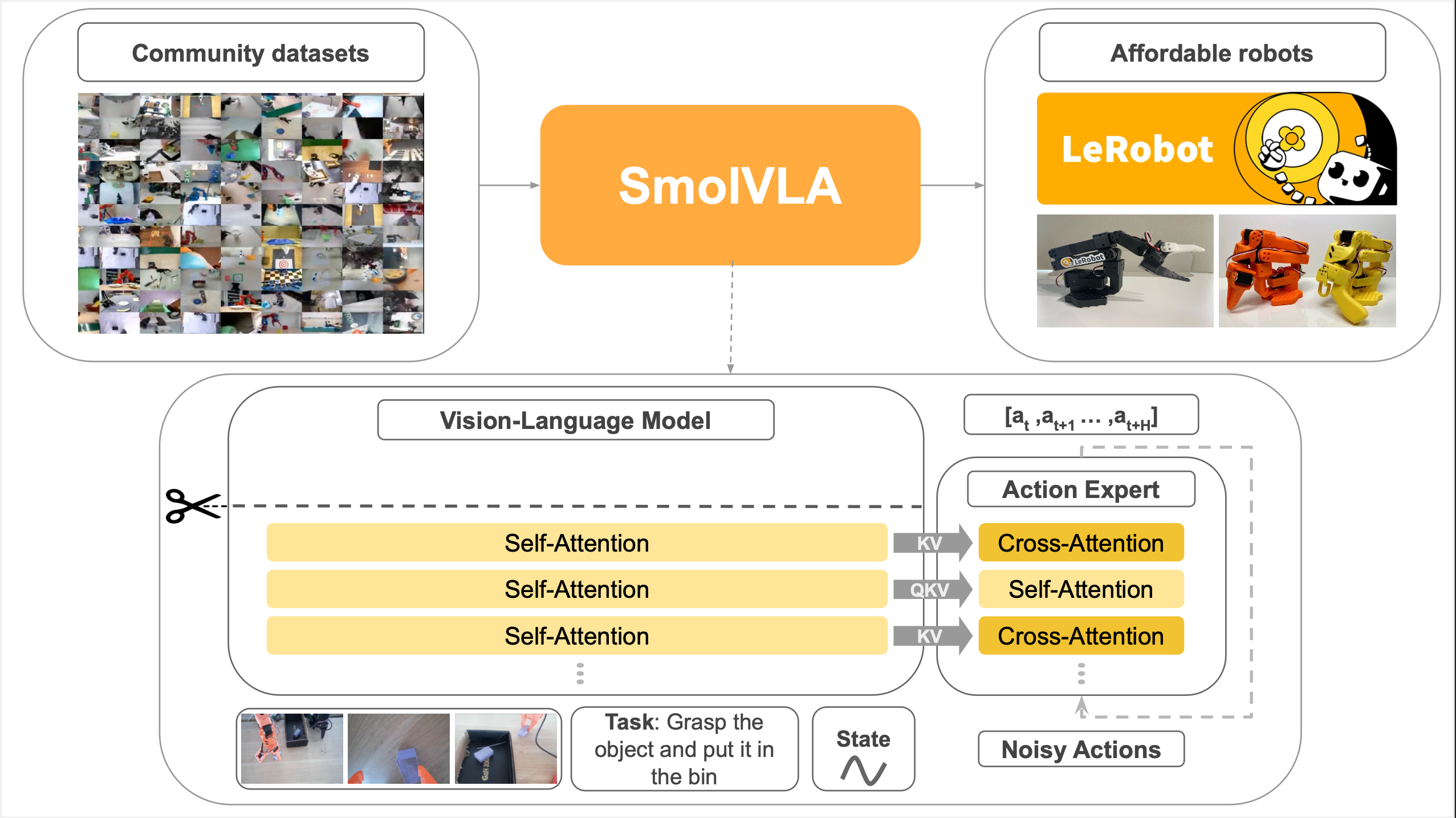
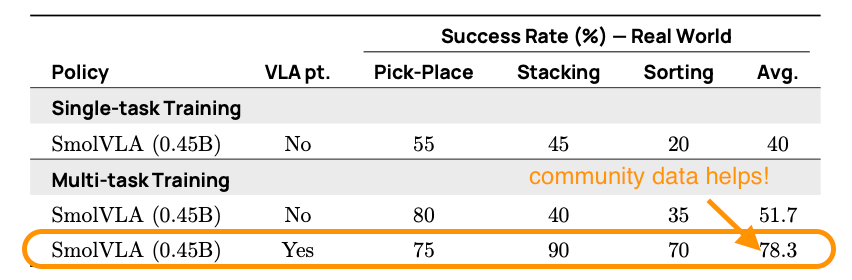
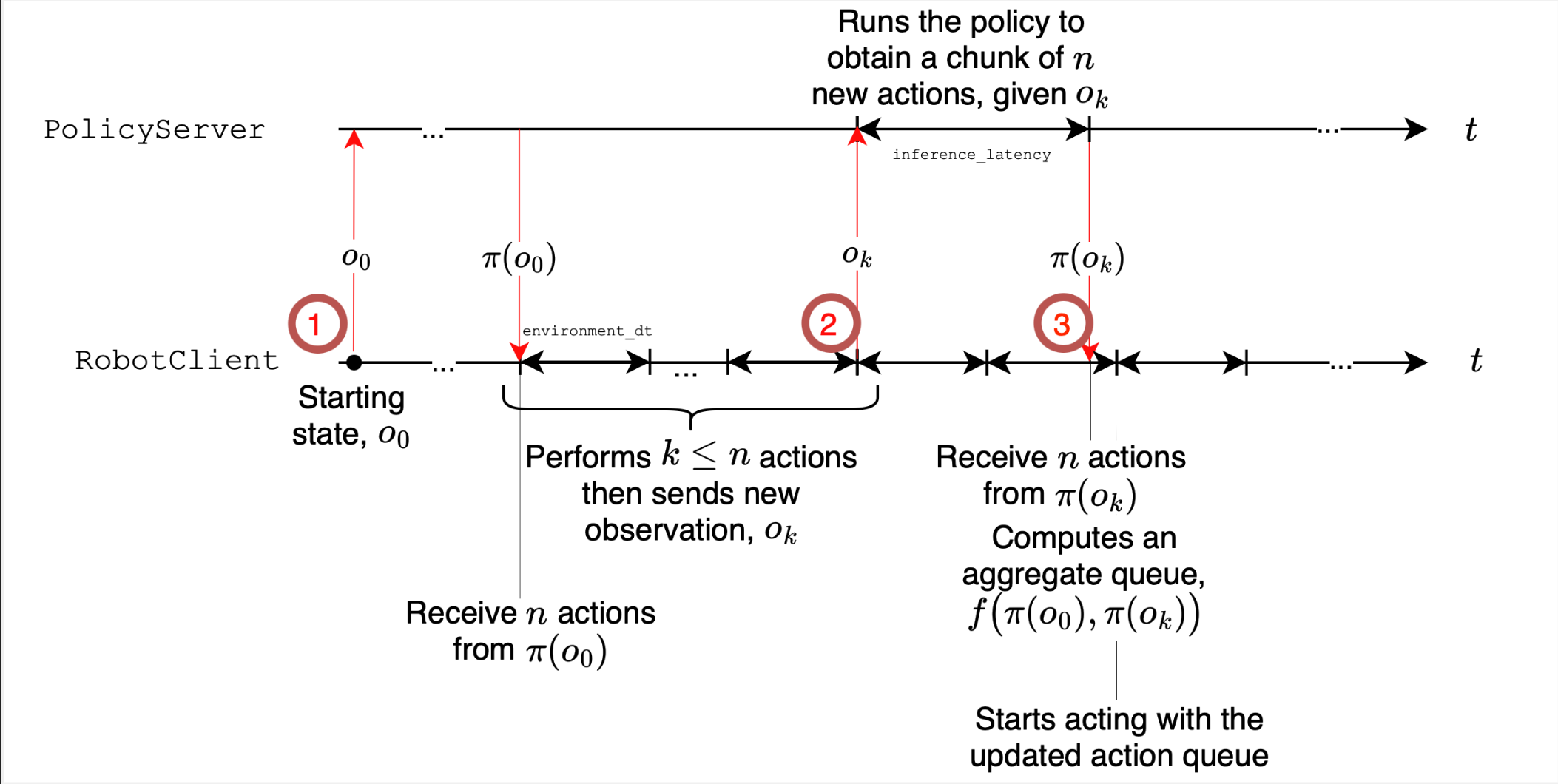
Smolvlaは、ロボット工学用のコンパクトな(450m)オープンソースビジョン言語アクションモデルです。コミュニティデータでトレーニングされ、消費者ハードウェアで実行され、より大きなモデルを上回ります。コードとレシピでリリースされました。