ProductHubX
ホーム
カテゴリ
タグ
ブログ
お気に入り
投稿
サインイン
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
日本語
サインイン
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
日本語
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
日本語
ホーム
カテゴリ
タグ
ブログ
お気に入り
投稿
サインイン
English
Español
简体中文
繁體中文
Français
Deutsch
Português
Русский
العربية
日本語
한국어
Italiano
Nederlands
हिन्दी
Türkçe
ไทย
Tiếng Việt
Bahasa Melayu
日本語
ホーム
カテゴリ
コードエディタ
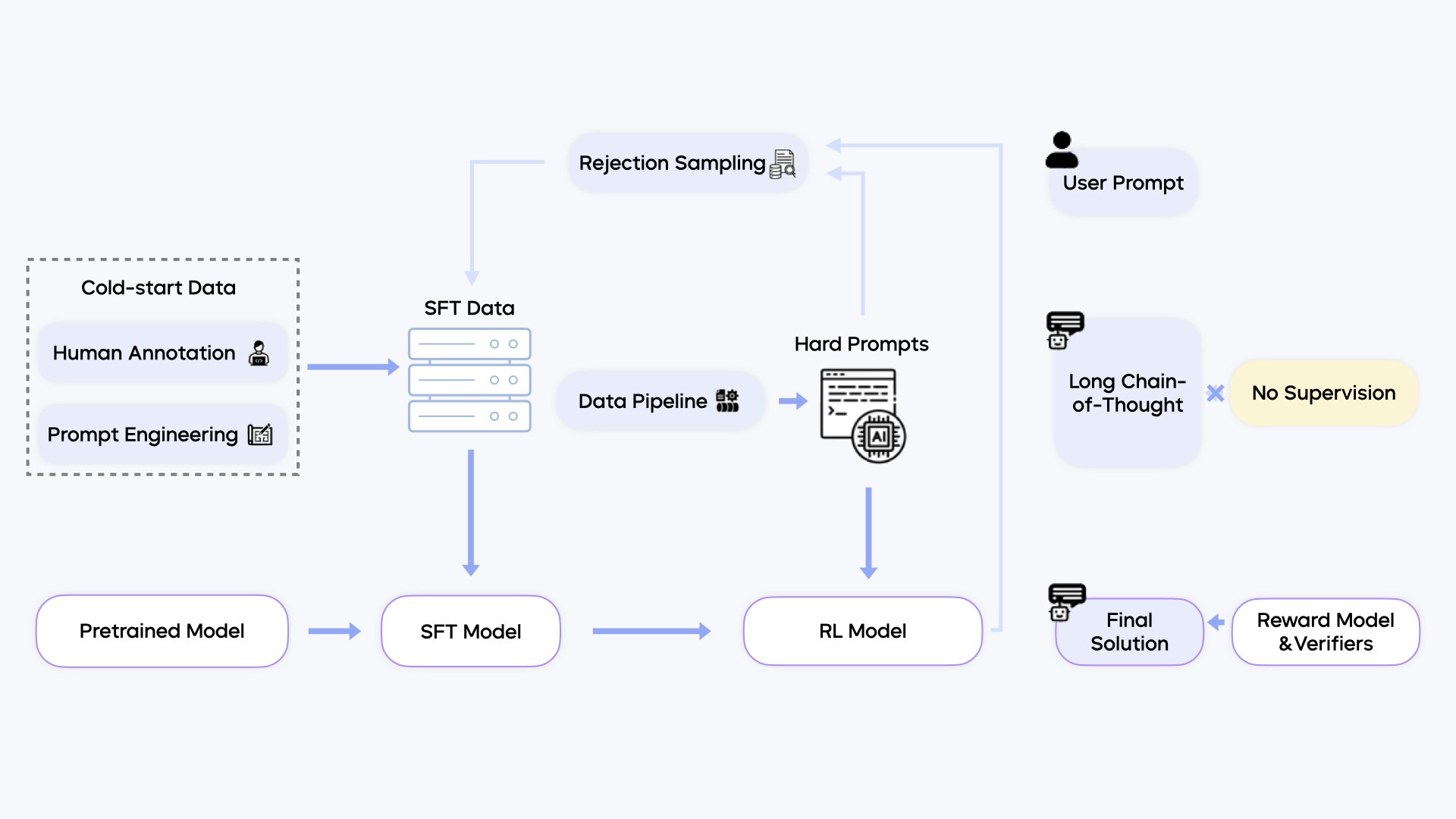
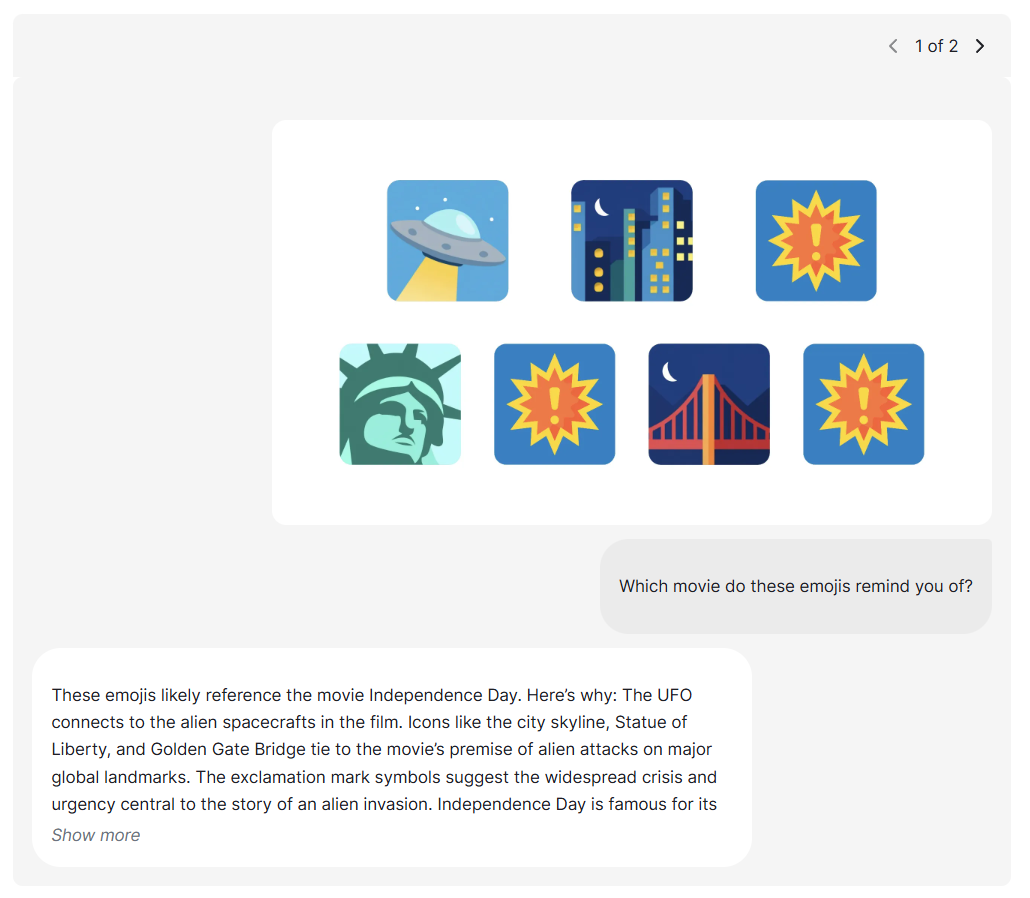
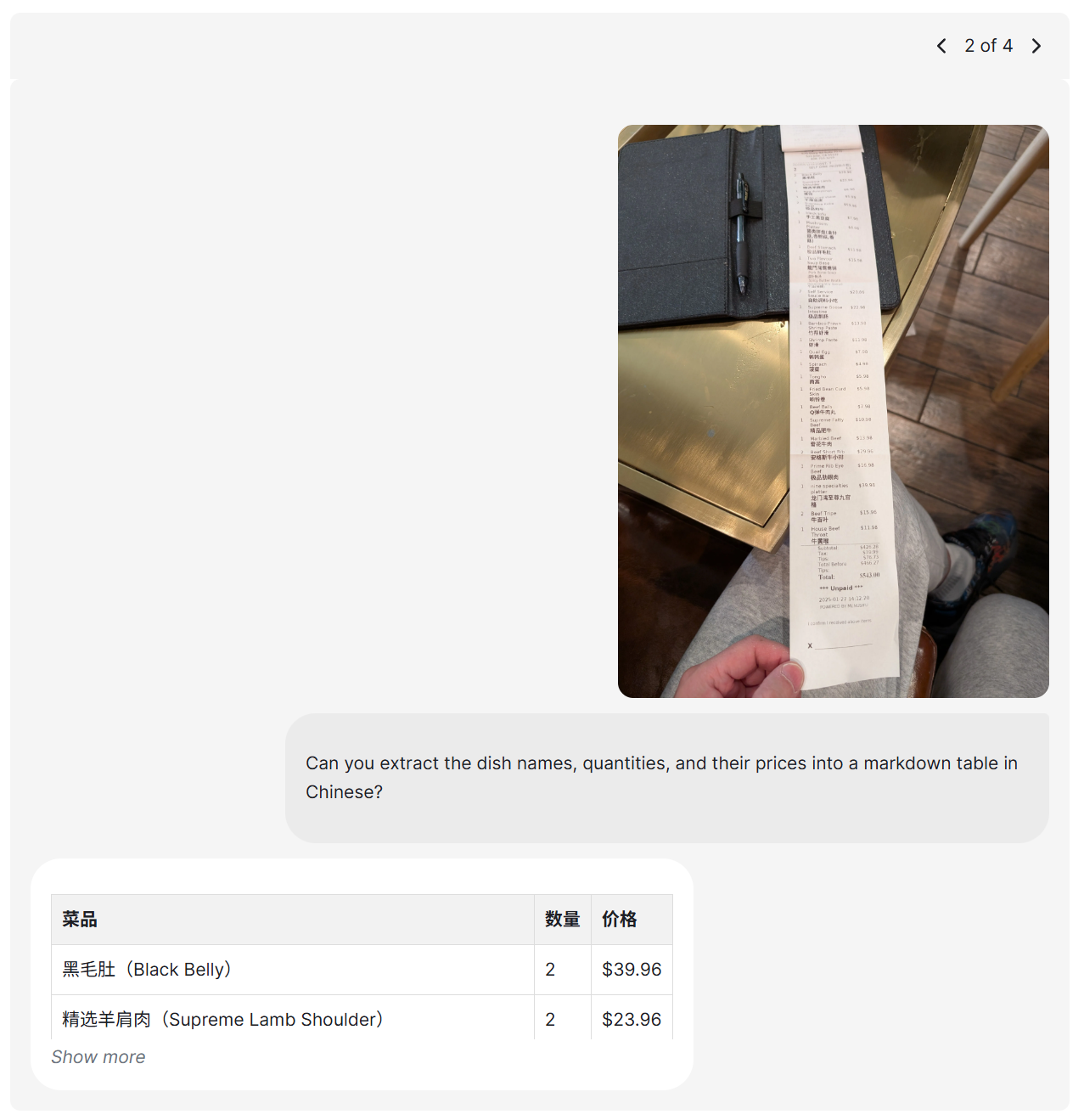
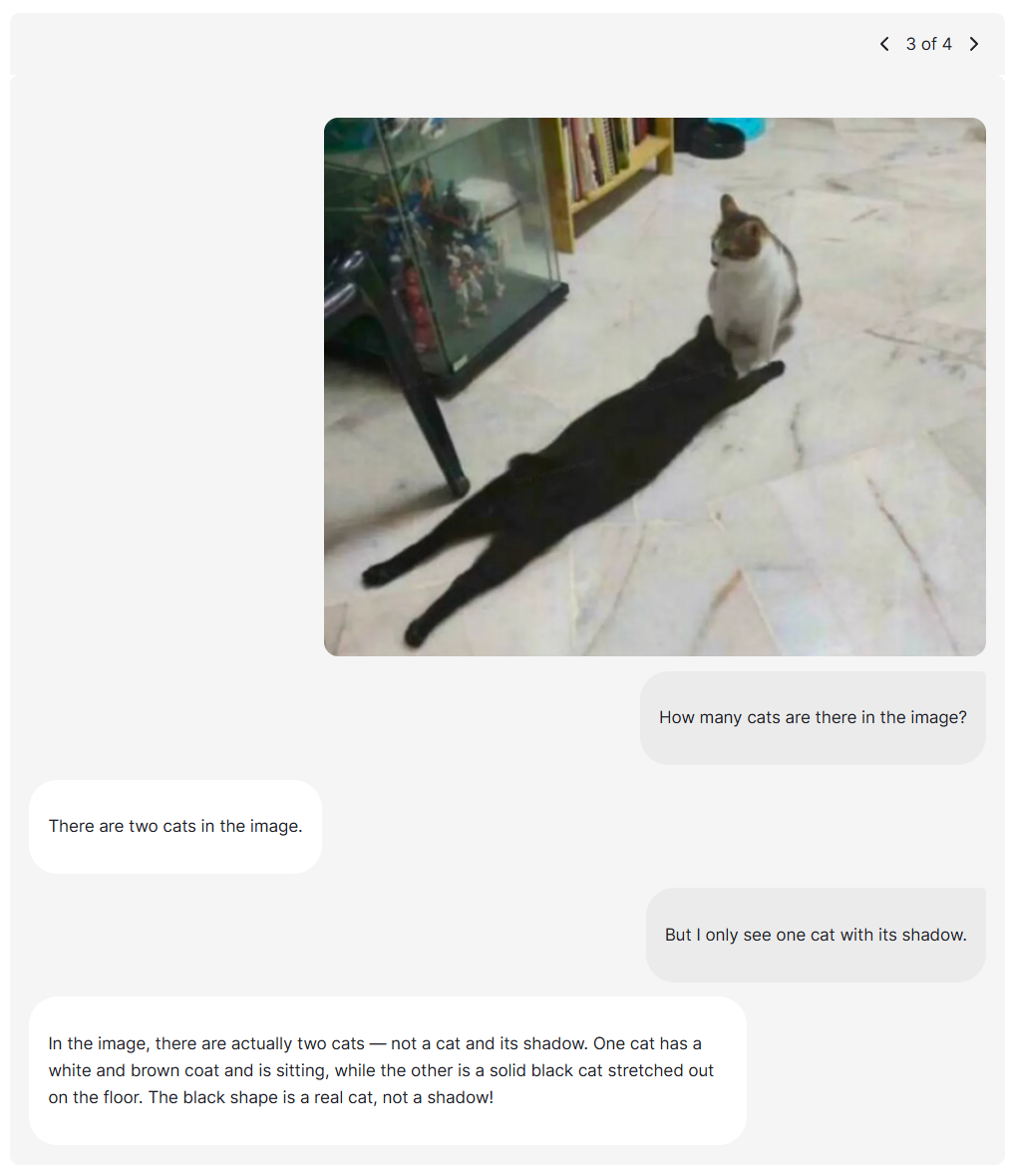
Seed1.5-Vl
Seed1.5-Vl
推論およびエージェントタスクのための高度なビジョン言語AI
注目
3 投票
ウェブサイトを訪問
説明
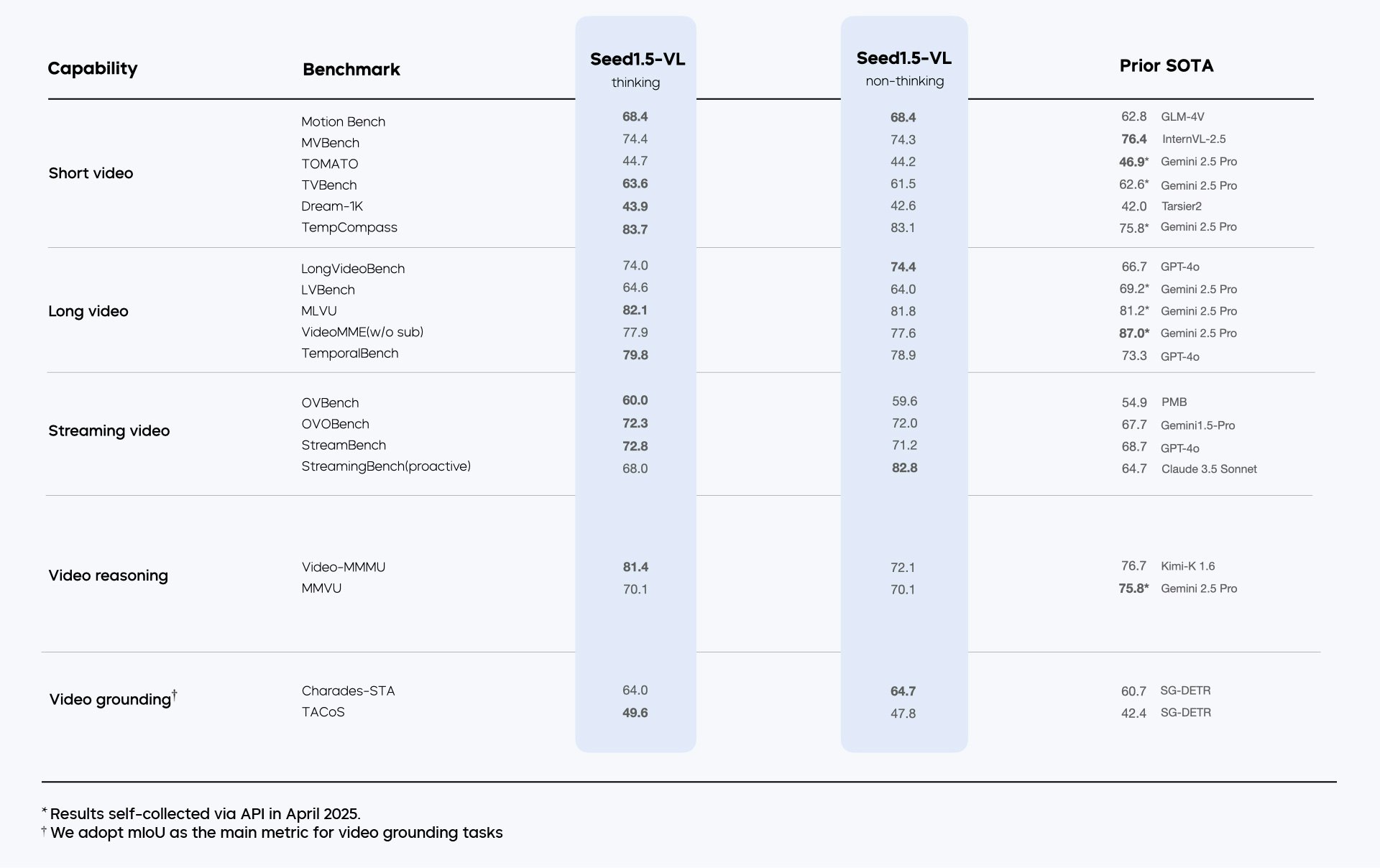
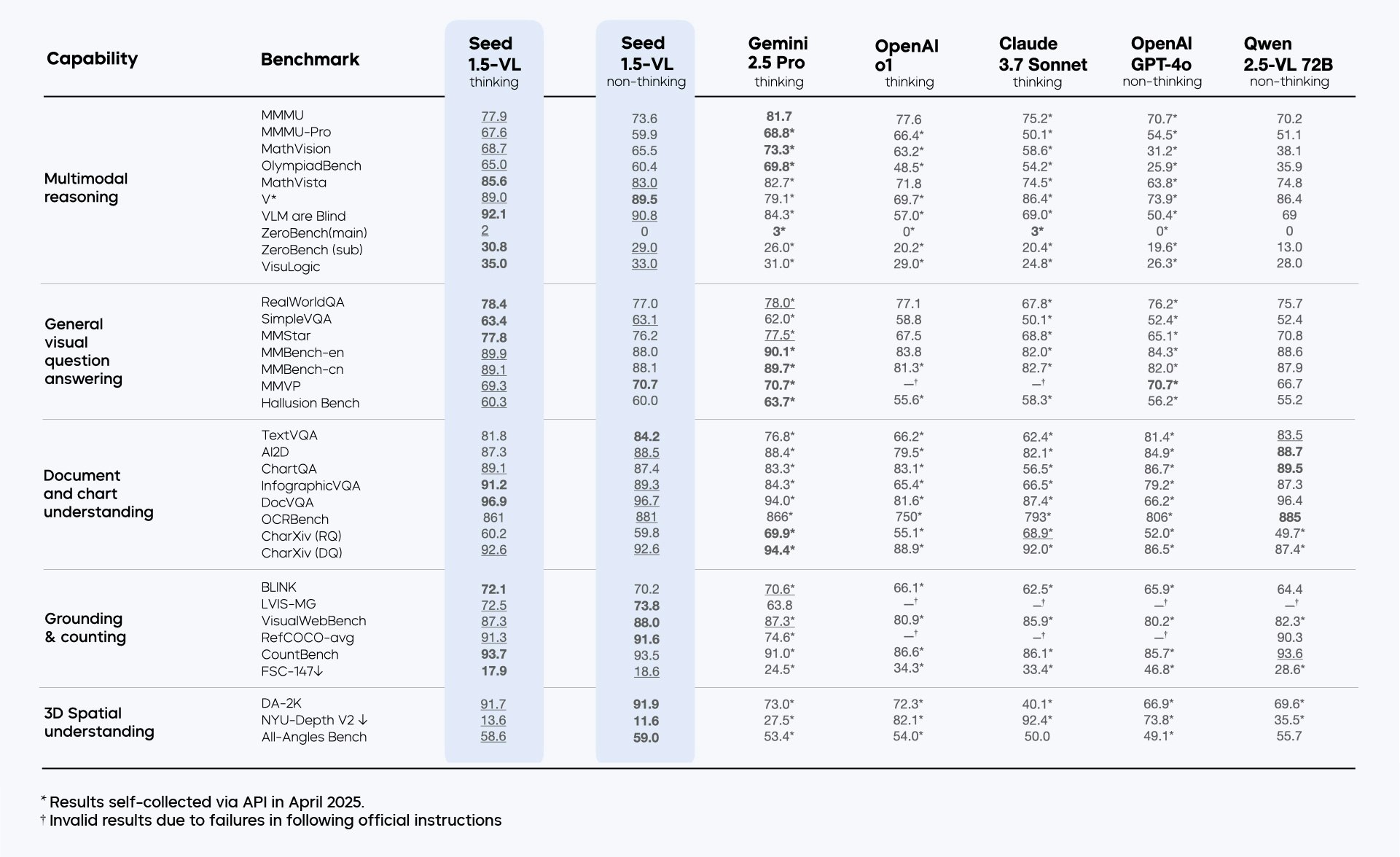
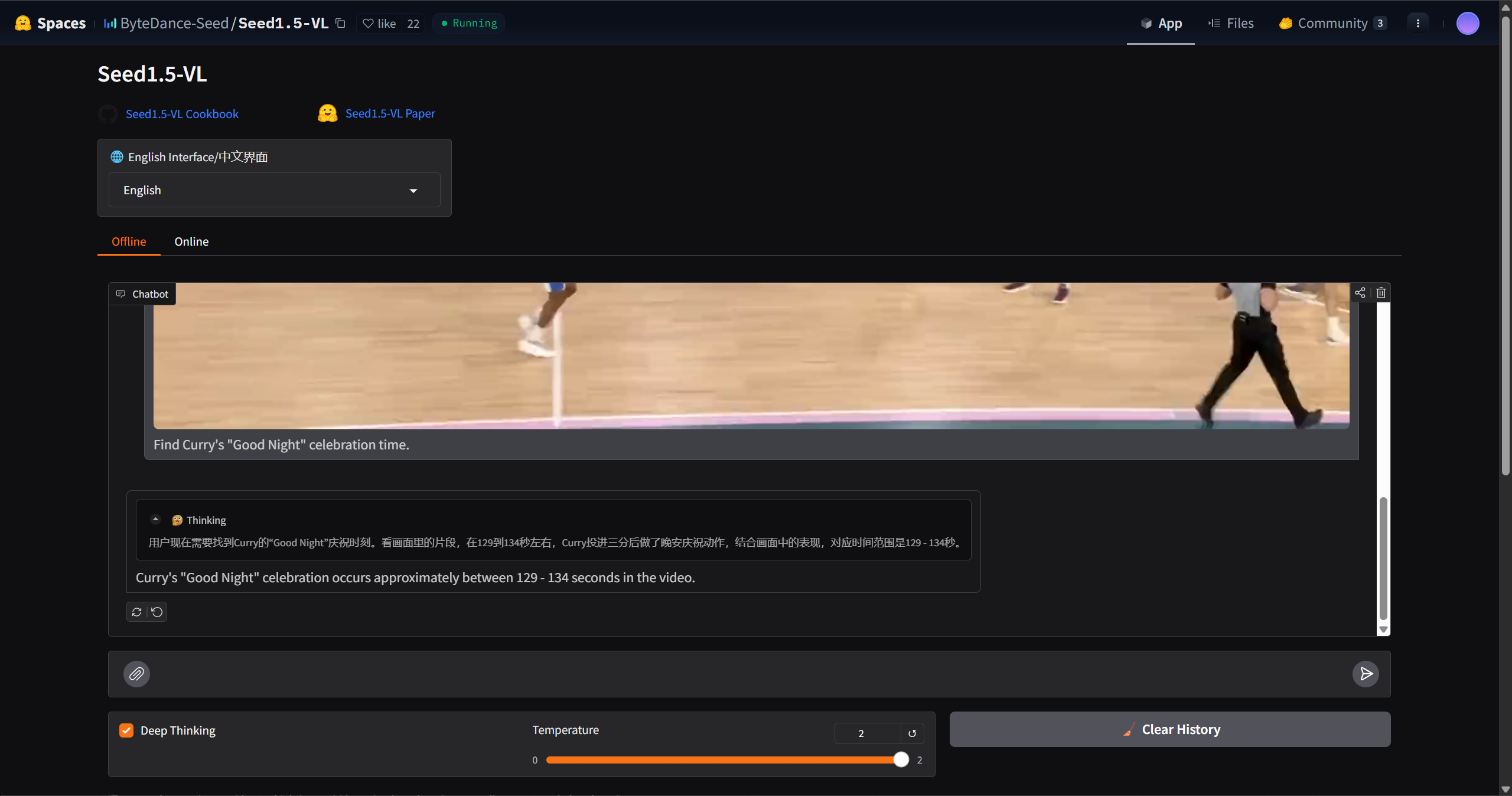
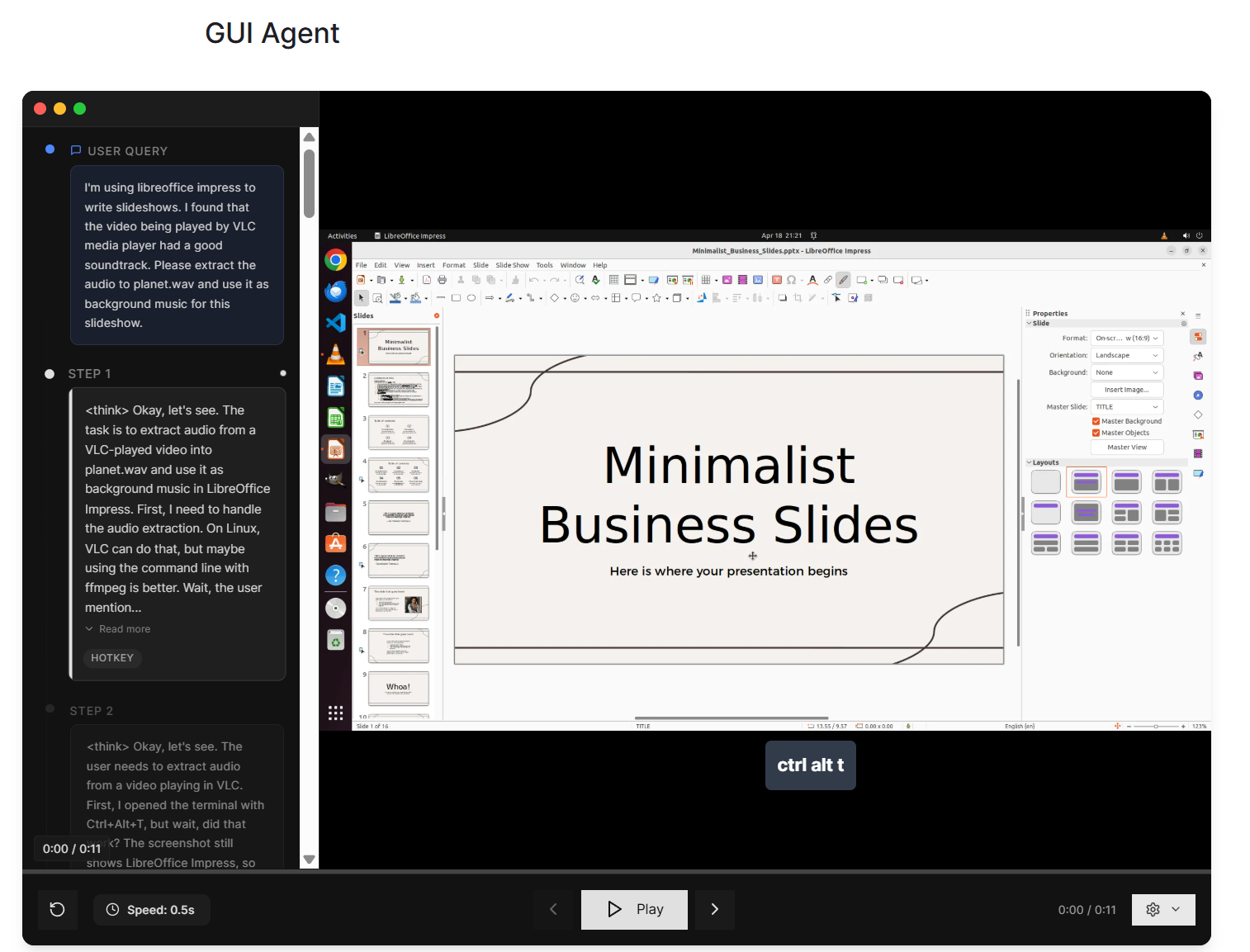
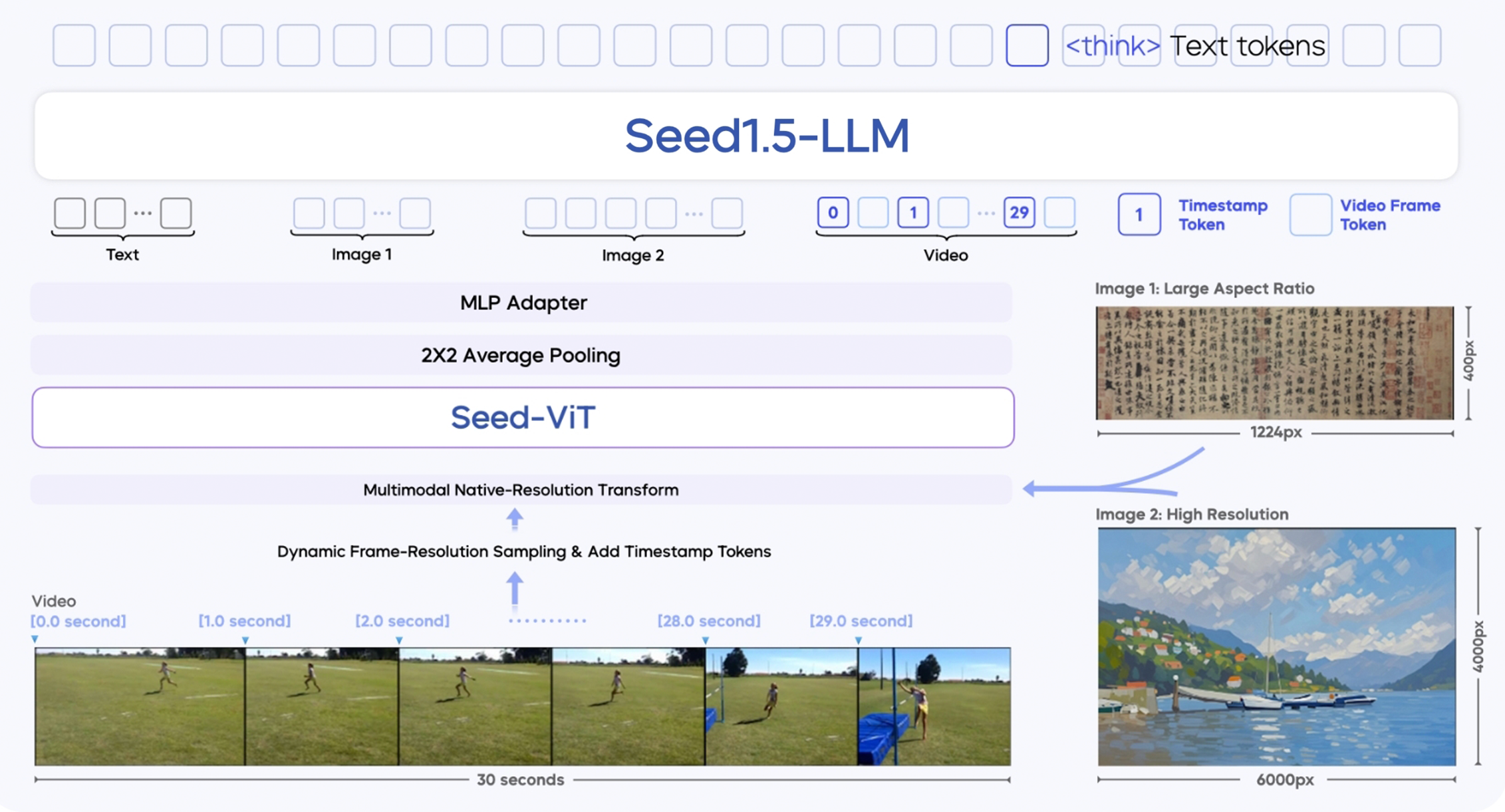
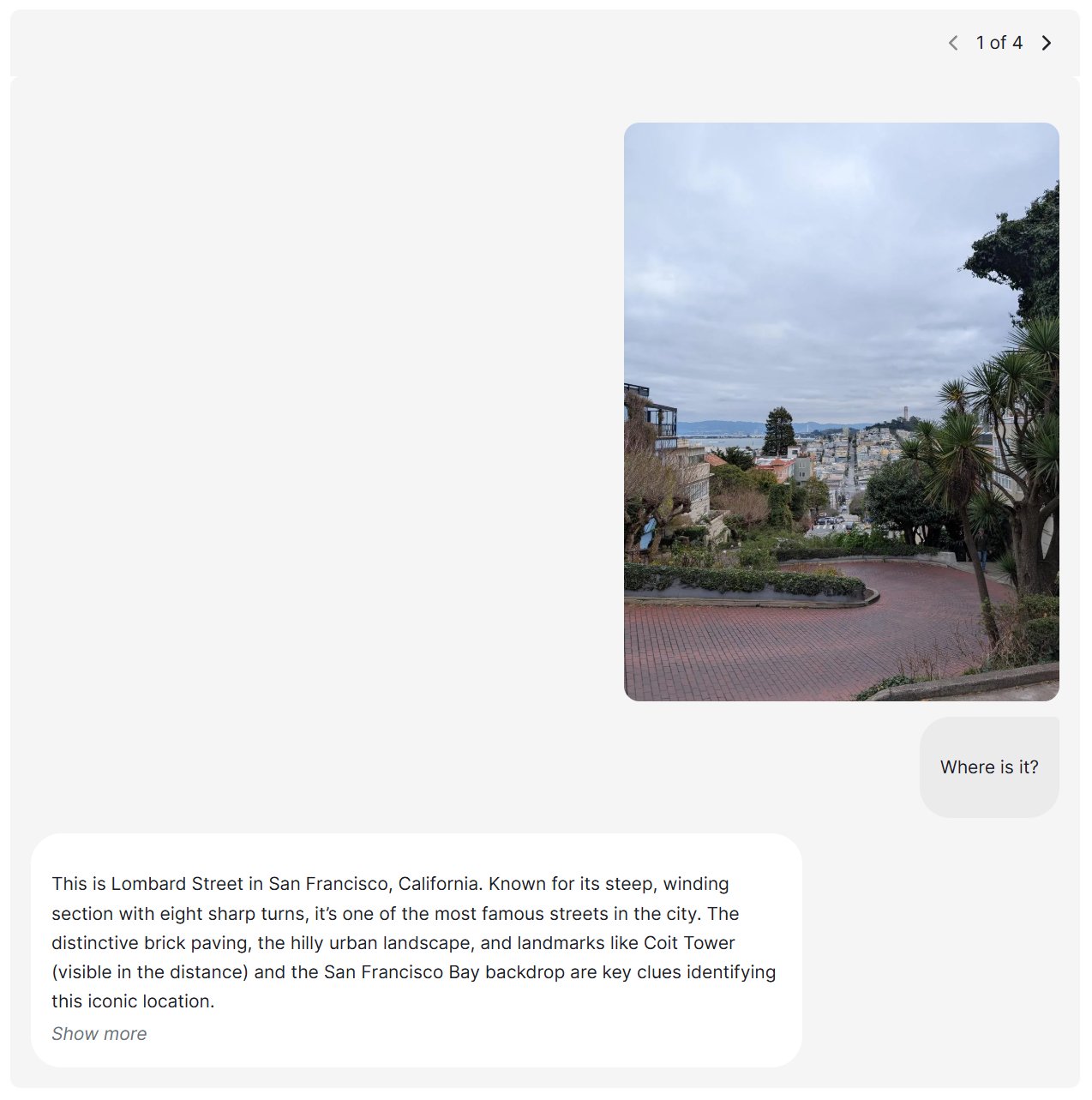
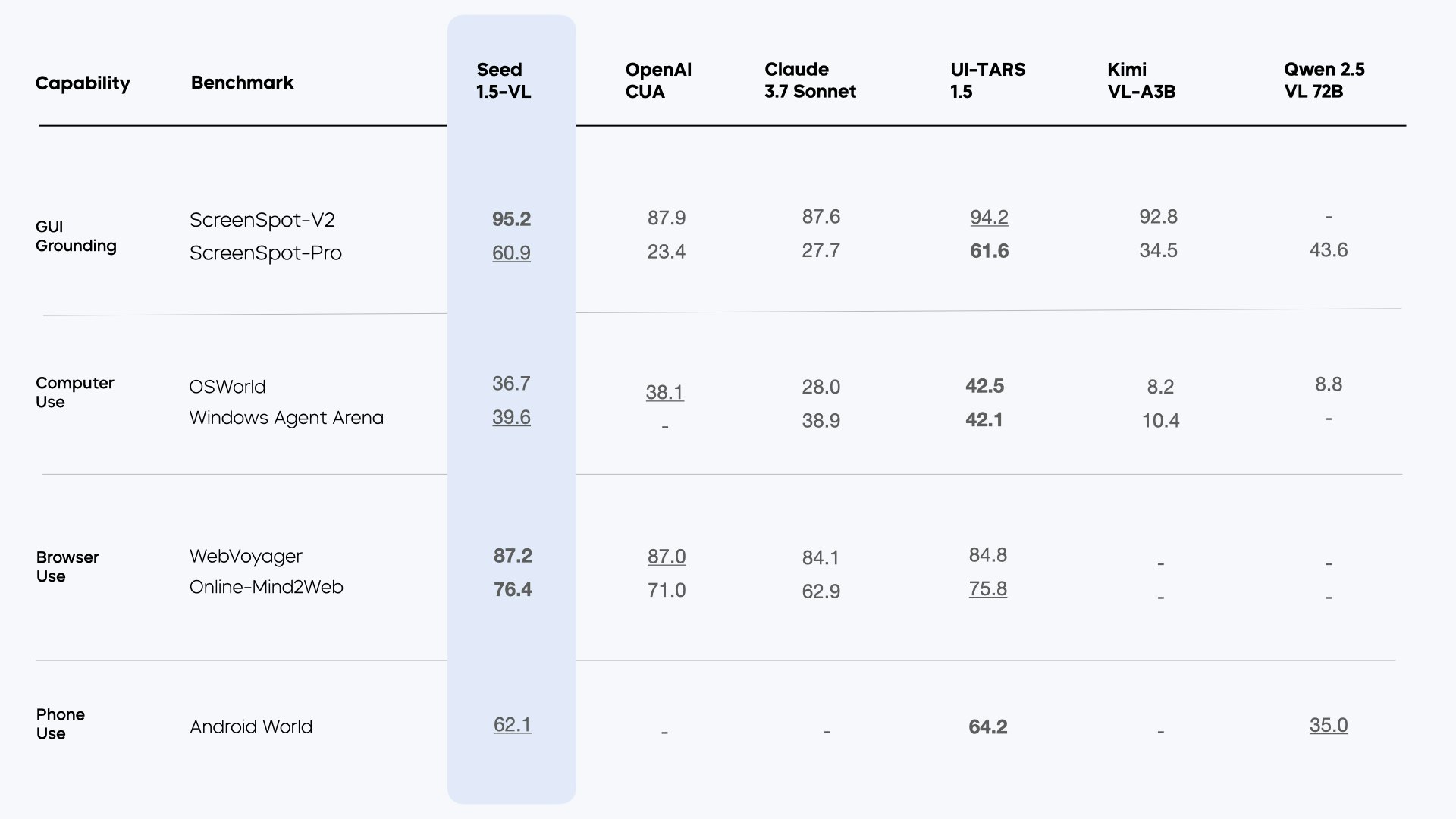
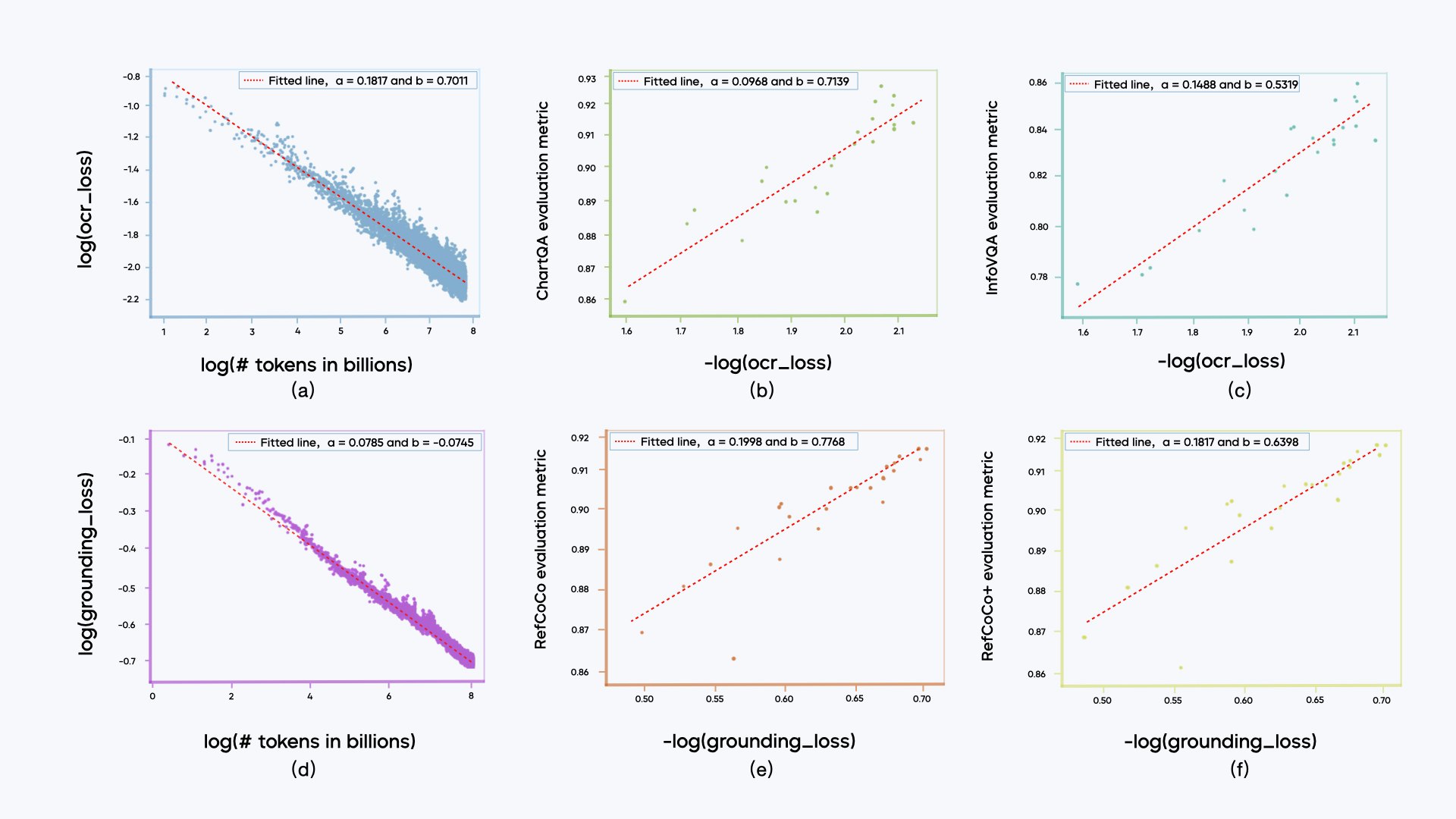
bytedance SeedによるSeed1.5-VLは、一般的なマルチモーダル理解、推論、エージェントタスクのための新しいビジョン言語基礎モデルです。38/60ベンチマークでSOTAを実現します。
カテゴリ
コードエディタ
Gitクライアント
タグ
人工知能
ギルブ
発達
写真とビデオ
推奨製品
ProductHubXアプリをインストール
このサイトはアプリケーションとしてインストールできます。独自のウィンドウで開き、OS機能と安全に統合されます。
今はしない
インストール
ProductHubXアプリをインストール
このサイトはアプリケーションとしてインストールできます。独自のウィンドウで開き、OS機能と安全に統合されます。
今はしない
インストール