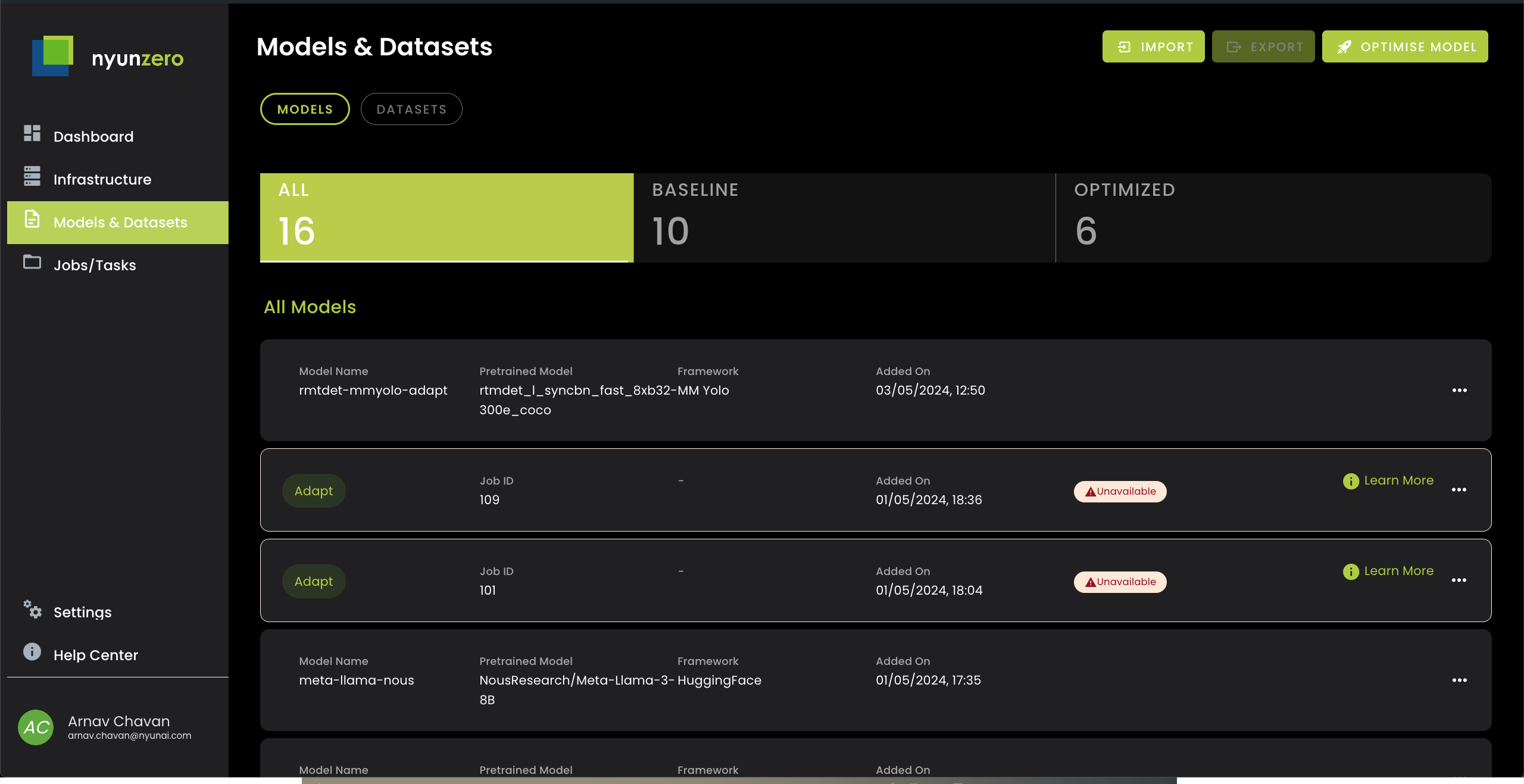
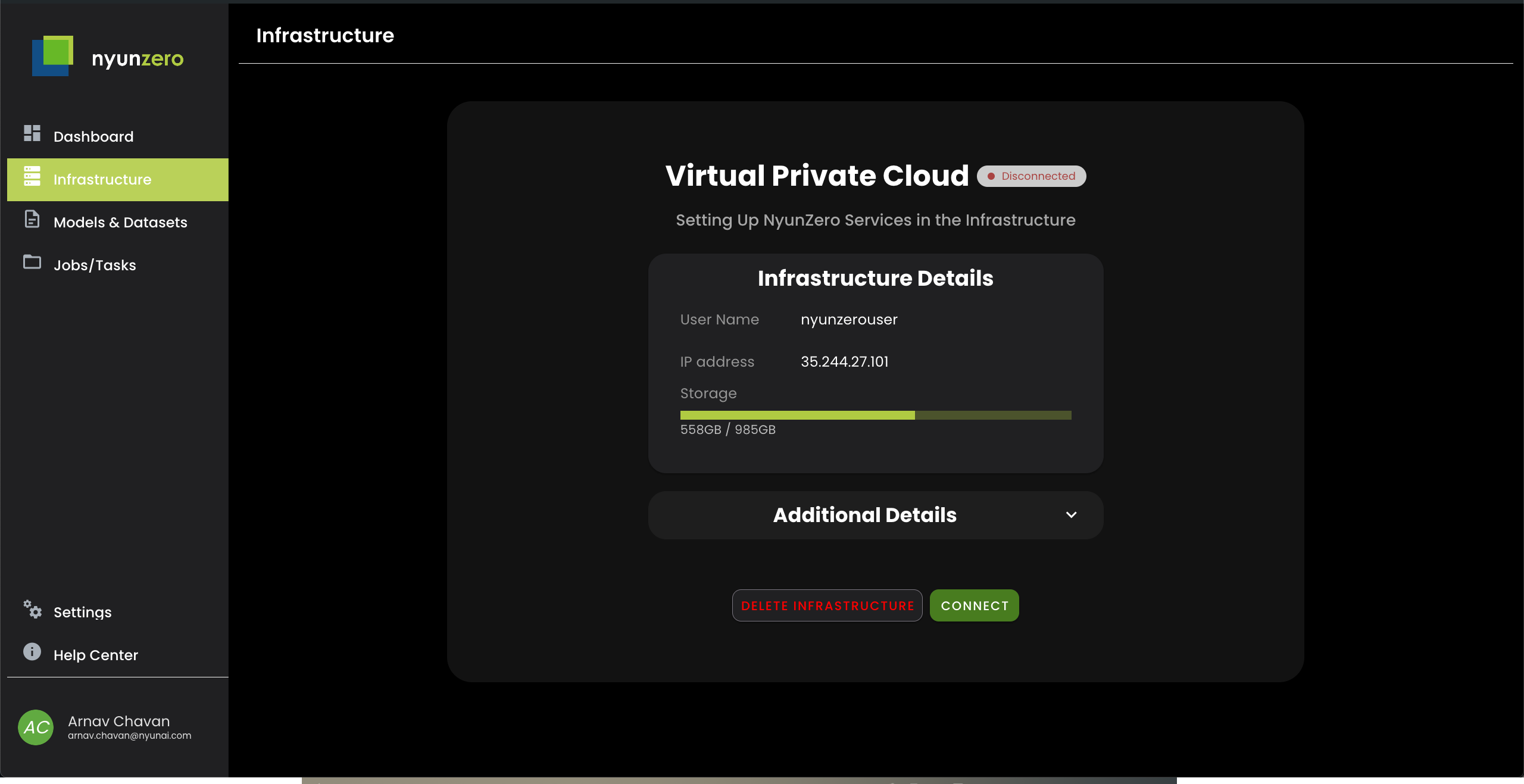
独自のインフラに接続し、ビジョンモデルとLLMの適応/圧縮を開始します。オブジェクト検出モデルをスピードアップするか、データに適応した数回のクリックで、Quantized Hardware互換のLLMを高速化します。docs -https://nyunai.github.io/nyun-docs/