Cache vecteur
Une bibliothèque Python pour la mise en cache de requête LLM efficace
En vedette
23 Votes
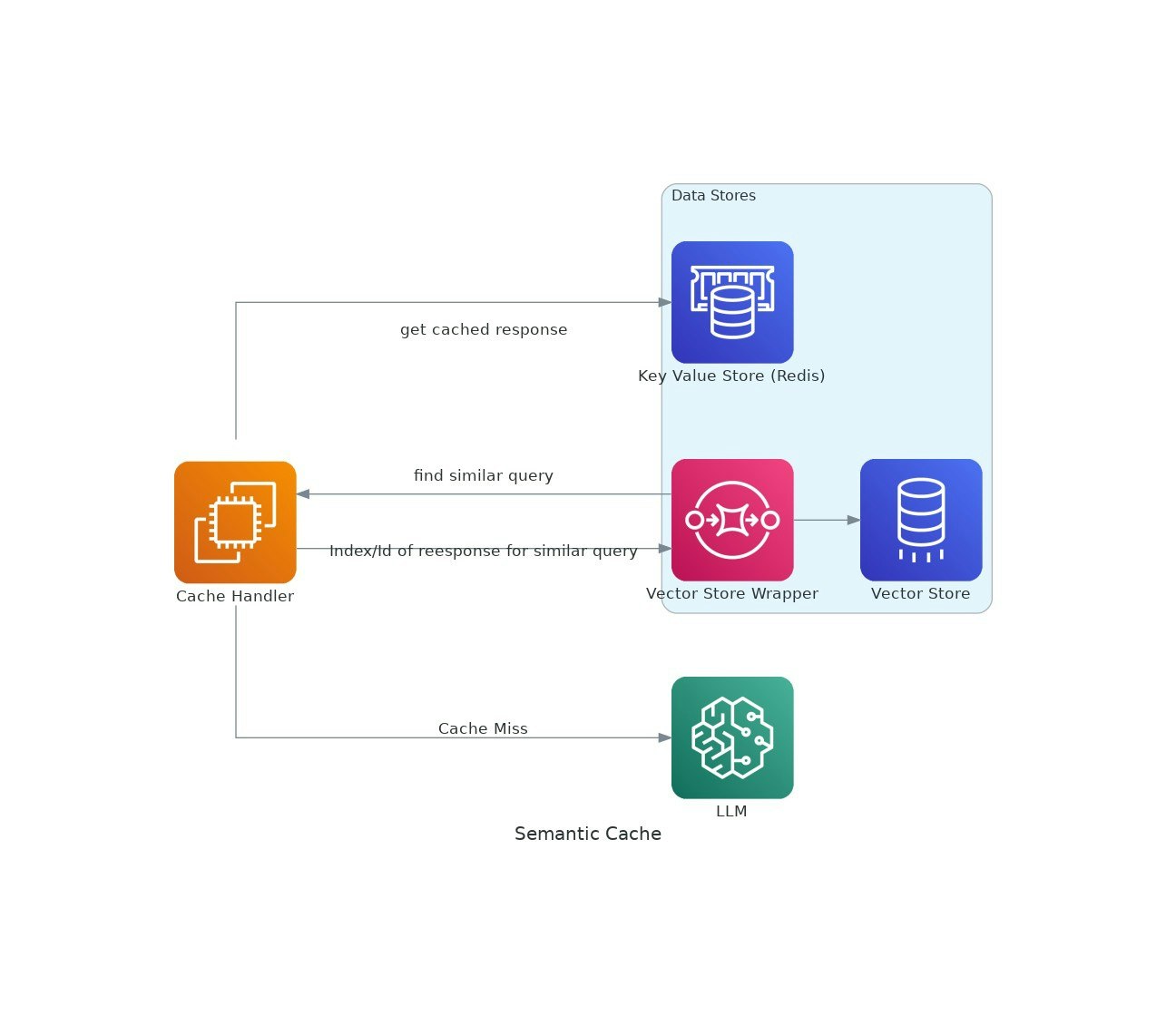
Description
Au fur et à mesure que les applications IA gagnent du terrain, les coûts et la latence de l'utilisation de modèles de langue importants (LLM) peuvent augmenter.VectorCache aborde ces problèmes en mettant en cache les réponses LLM basées sur la similitude sémantique, réduisant ainsi à la fois les coûts et les temps de réponse.