G.
Hyperfast LLM fonctionnant sur des GPU construits sur mesure
En vedette
213 Votes


Description
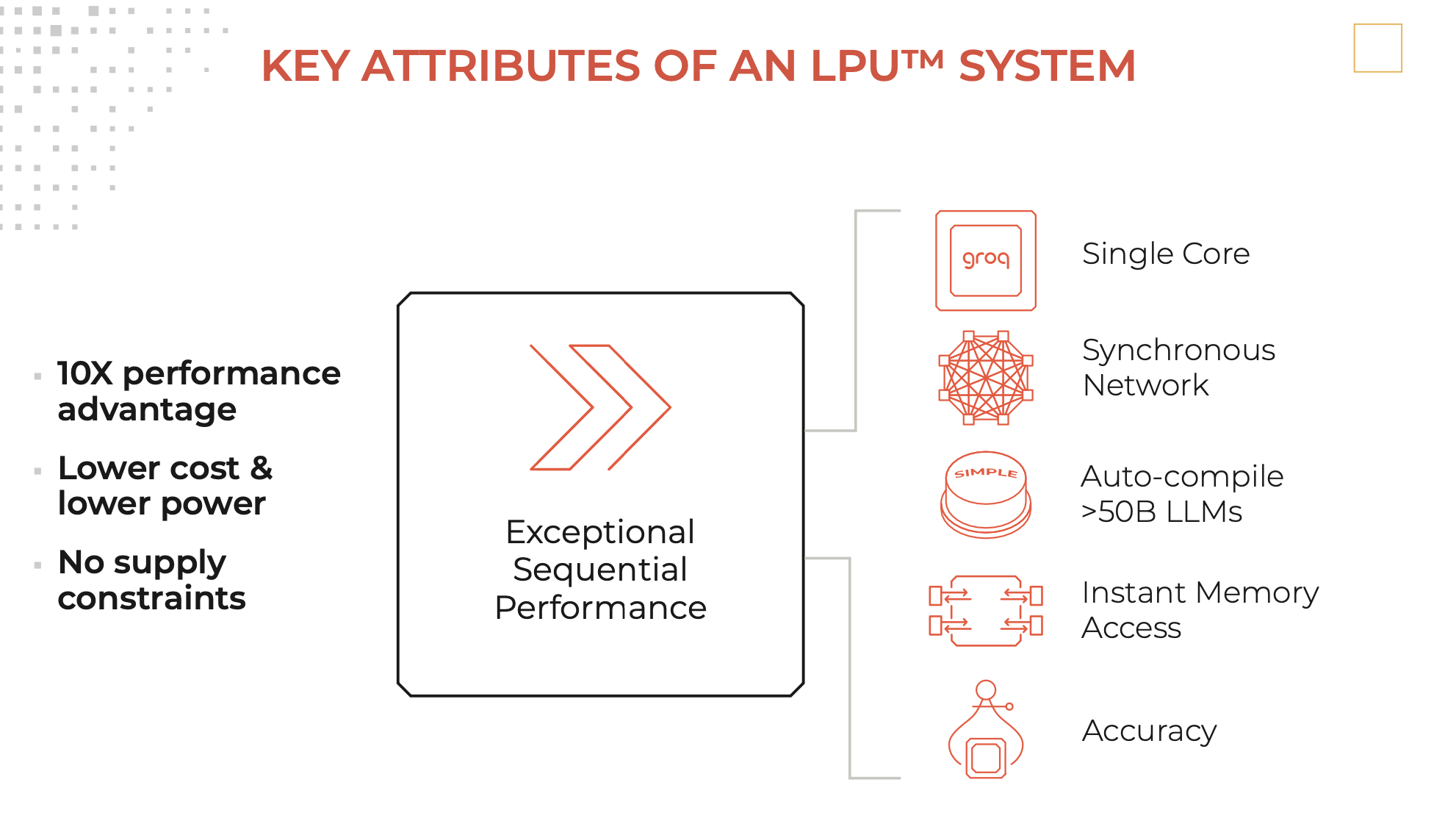
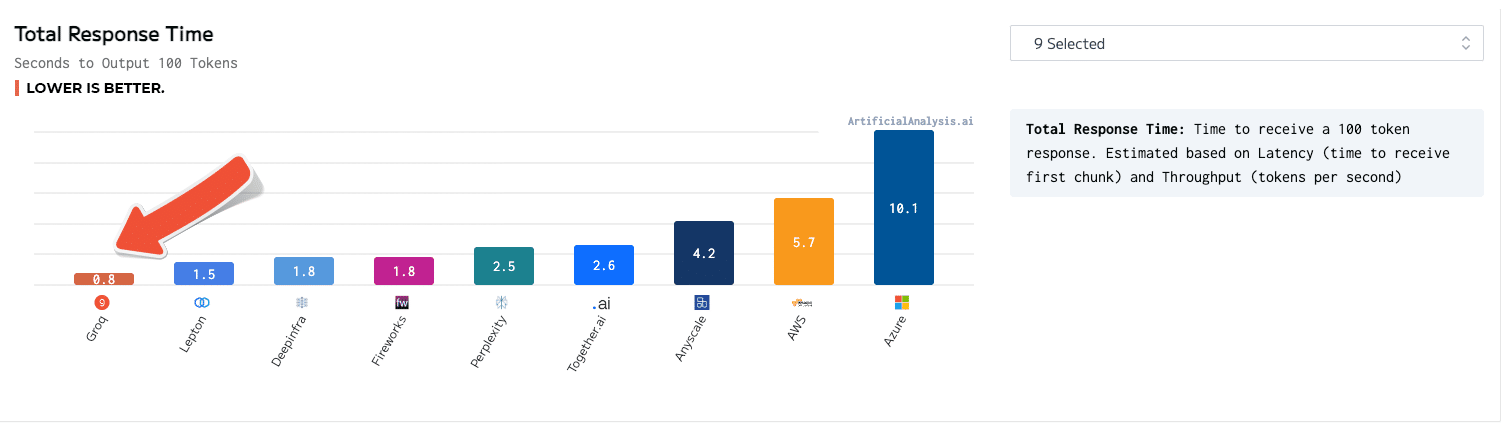
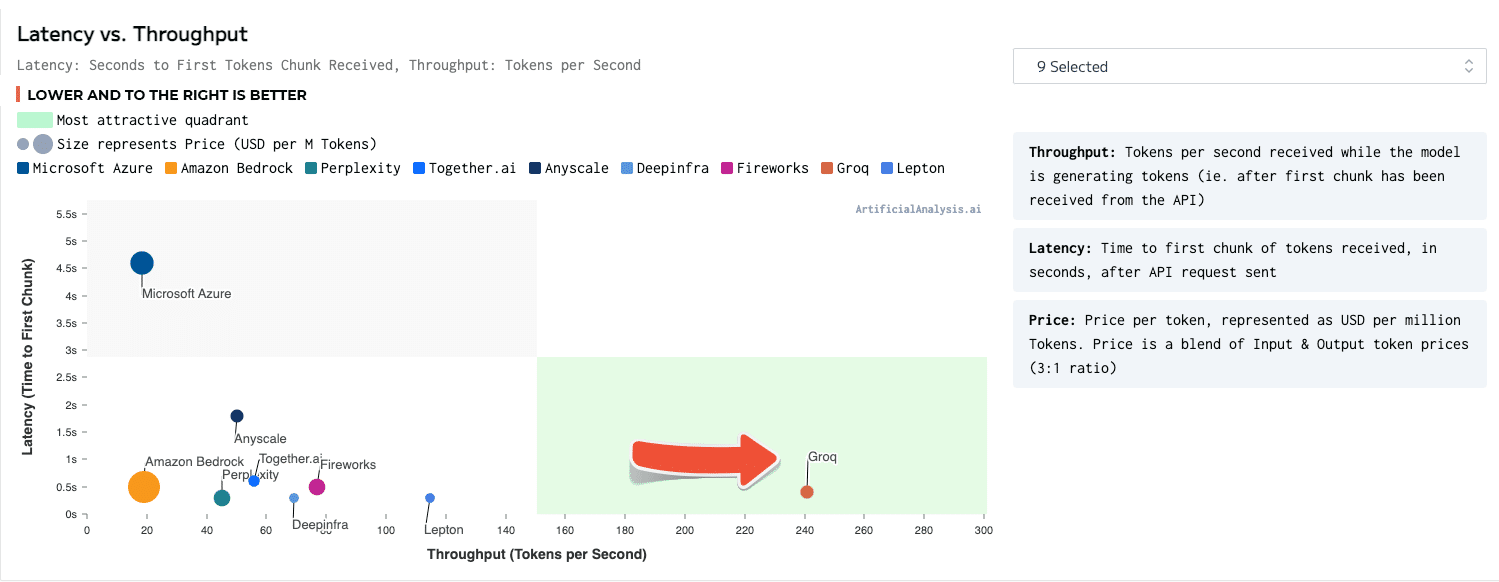
Un moteur d'inférence LPU, avec LPU pour le langage de traitement du langage ™, est un nouveau type de système d'unité de traitement de bout en bout qui fournit l'inférence la plus rapide à ~ 500 jetons / seconde.