Caché de vector
Una biblioteca de Python para caché de consultas de consultas eficientes
Destacado
23 Votos
Descripción
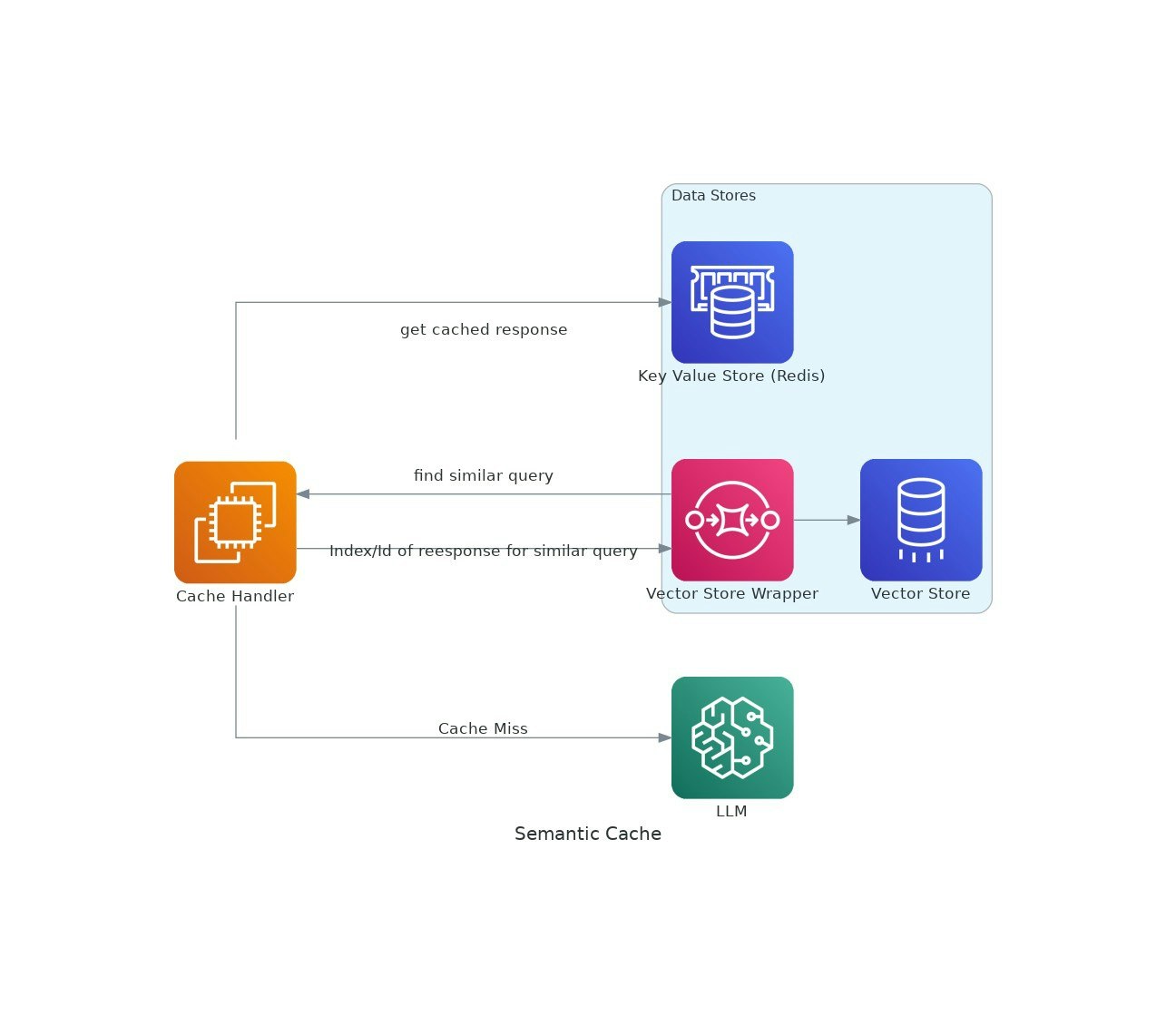
A medida que las aplicaciones de IA ganan tracción, los costos y la latencia del uso de modelos de idiomas grandes (LLM) pueden aumentar.VectorCache aborda estos problemas al almacenar en caché las respuestas LLM en función de la similitud semántica, reduciendo así los costos y los tiempos de respuesta.