GRAMO.
Hyperfast LLM ejecutándose en GPU personalizadas
Destacado
213 Votos

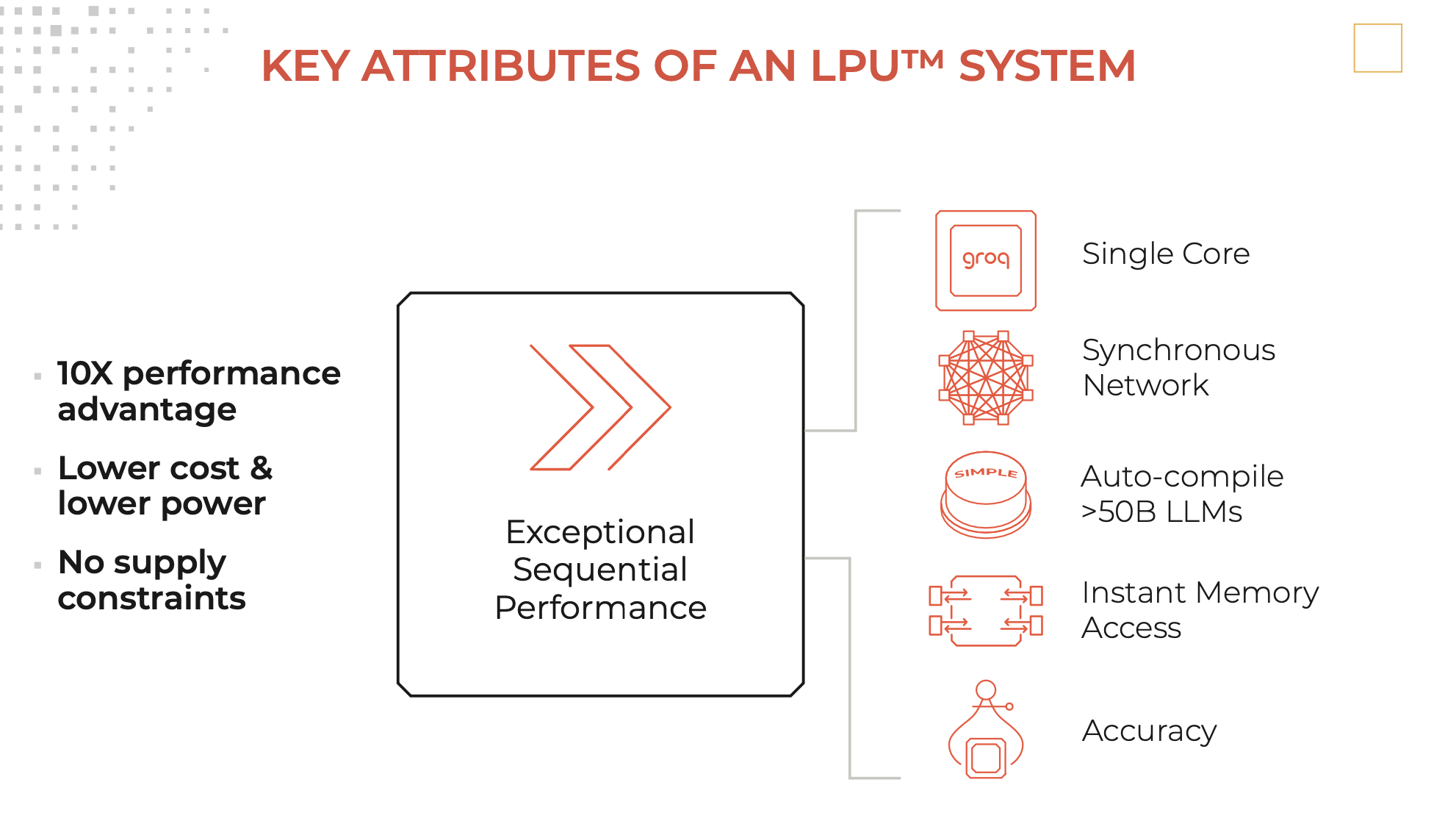

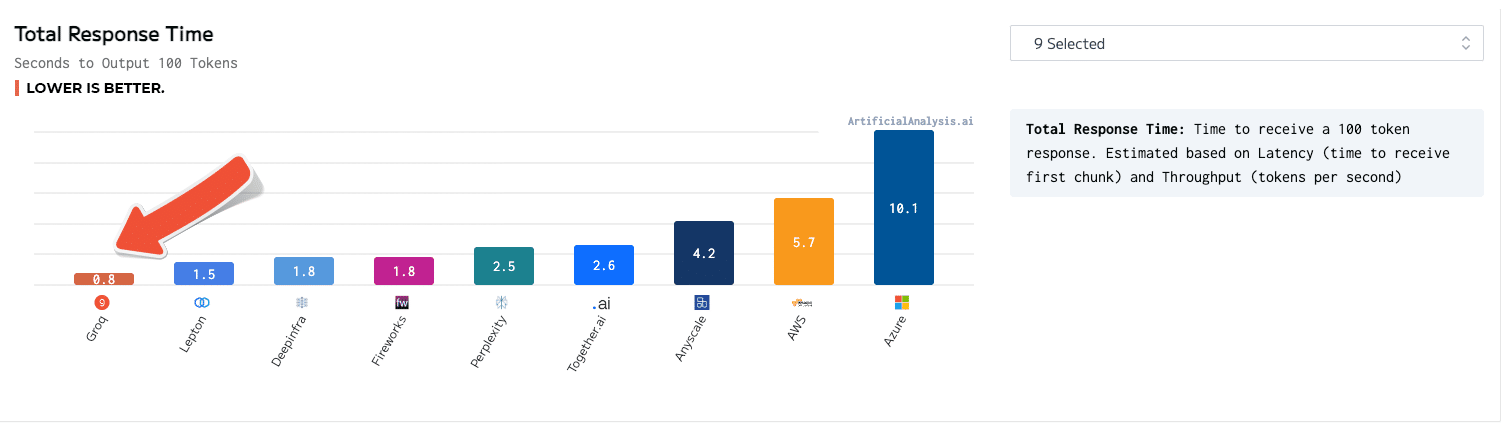
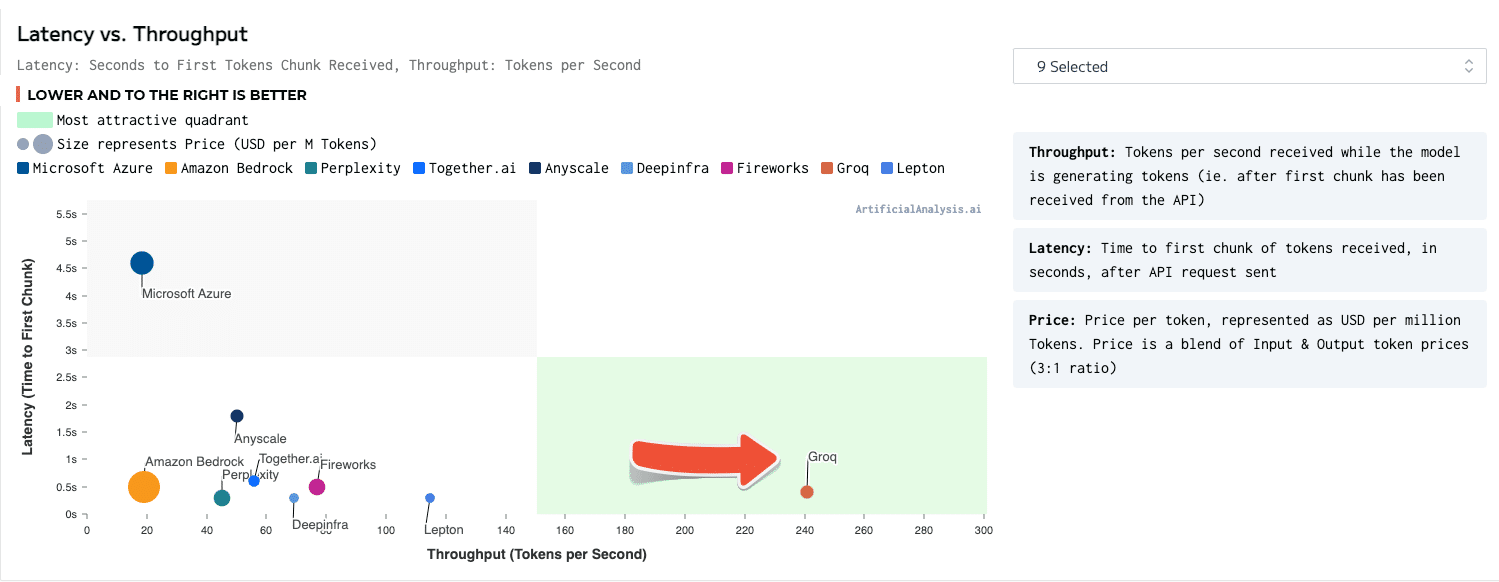
Descripción
Un motor de inferencia de LPU, con LPU que representa la Unidad de procesamiento del lenguaje ™, es un nuevo tipo de sistema de unidad de procesamiento de extremo a extremo que proporciona la inferencia más rápida a ~ 500 tokens/segundo.