Flashmla
Inferencia LLM más rápida en GPU de Hopper
Destacado
5 Votos

Descripción
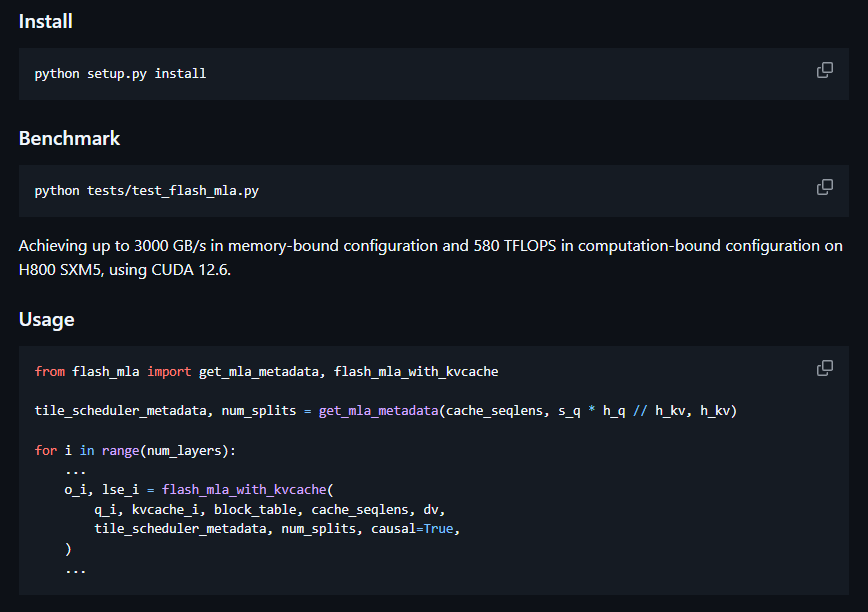
Flashmla, de Deepseek, es un kernel de decodificación MLA eficiente para GPU de la tolva, optimizado para secuencias de longitud variable.Logra hasta 3000 GB/s ancho de banda de memoria y 580 tflops.