kit de rastreo
Web scraping, simplificado.
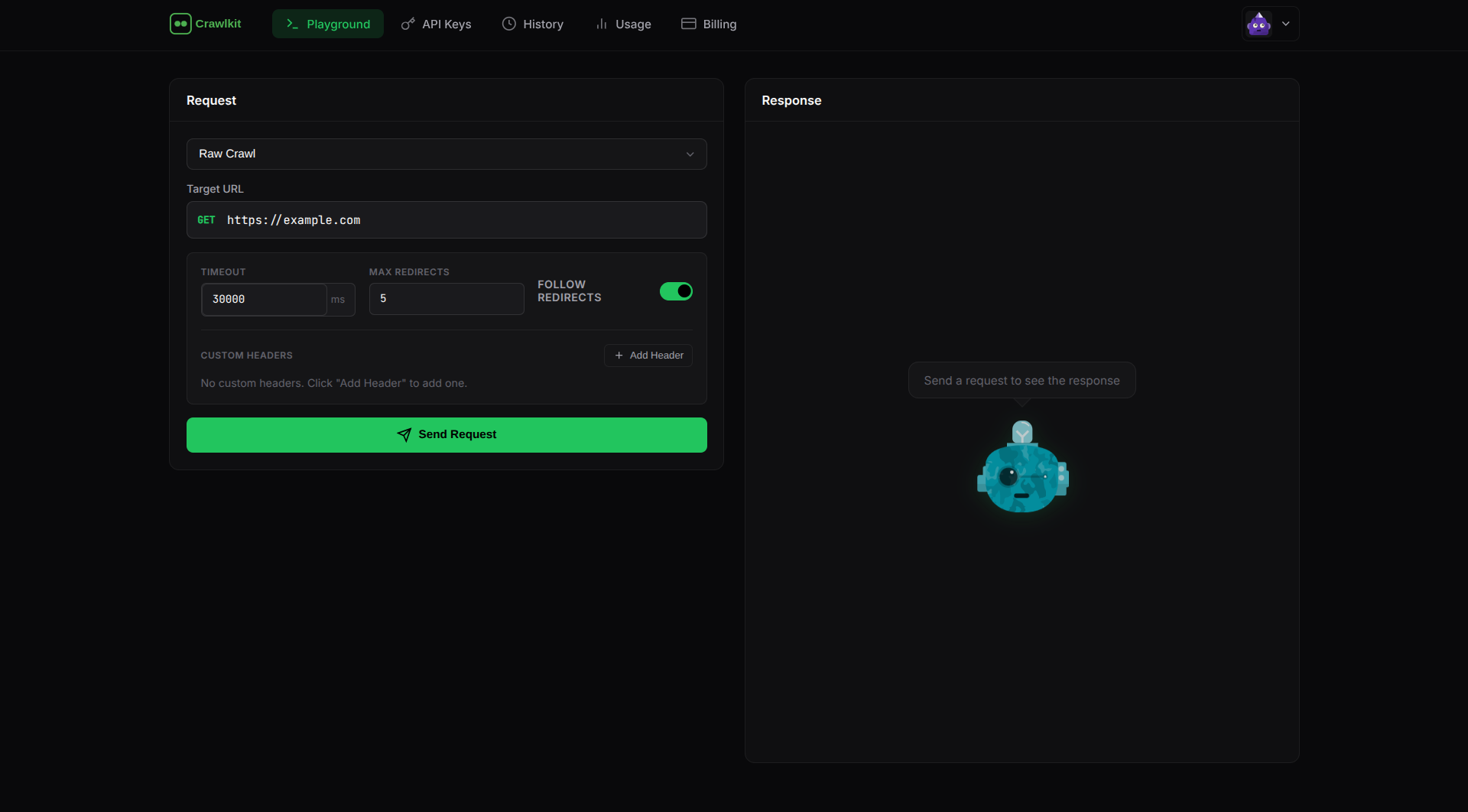
Descripción
CrawlKit es una plataforma de extracción de datos web diseñada para desarrolladores y equipos de datos que necesitan acceso confiable y escalable a datos web sin construir ni mantener una infraestructura de scraping.
El web scraping moderno generalmente significa lidiar con proxies rotativos, navegadores sin cabeza, protecciones anti-bot, límites de velocidad y fallas constantes.CrawlKit elimina toda esa complejidad.Usted envía una solicitud y CrawlKit maneja la rotación del proxy, la representación del navegador, los reintentos y el bloqueo, para que pueda concentrarse en usar los datos, no en recopilarlos.
Con CrawlKit, puede extraer múltiples tipos de datos web a través de una interfaz única y consistente: contenido de página sin procesar, resultados de búsqueda, instantáneas visuales y datos profesionales de LinkedIn.